transformer学习 & Attention is all you need 论文阅读笔记 & 代码层面学习
带我的学长发了篇论文给我 让我学一下 Multi-attention 开始动工了~~
学习路线
学习路线
- 李宏毅机器学习 self-attention
- 读论文 attention is all you need
- https://luweikxy.gitbook.io/machine-learning-notes/self-attention-and-transformer
争取结合自己的理解用最短的话概括论文核心内容
论文阅读
Introduction
transformer 的优点 – RNN时序从前往后计算, 而 transformer 可以并行计算,能够提升计算速度。
Background
如何用卷积神经网络替换掉循环神经网络。
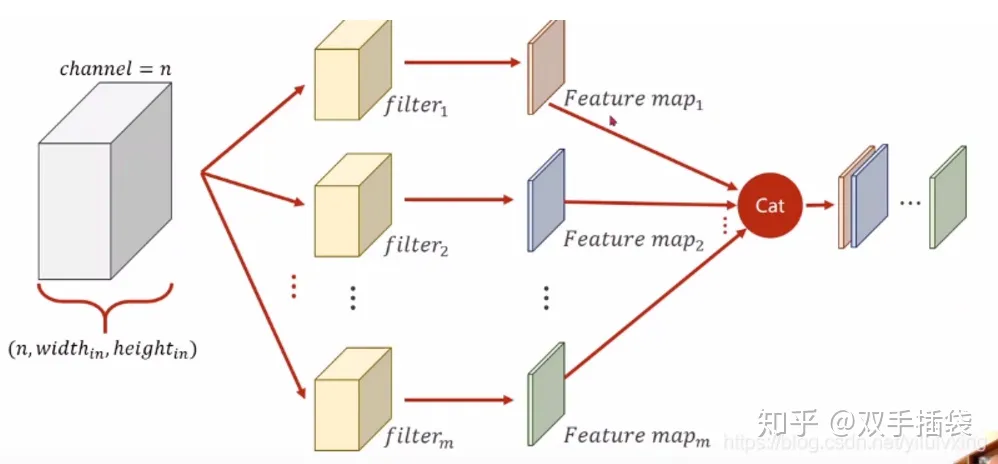
卷积神经网络对比较长的序列难以建模,使用他的 attention 机制, 可以抵消这种影响。卷积比较好的地方是可以做多通道输出(这里应该是我下面写的第二种,一个输出通道可以认为是去识别不一样的模式),这里用 Multi-Head Attention 来实现。
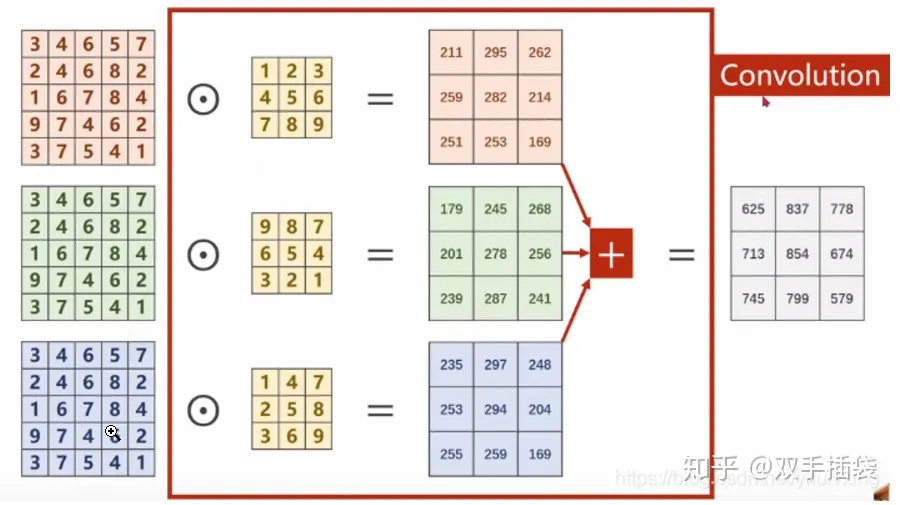
多通道卷积的意思
- 图片上的多通道
最终得到的卷积结果是原始图像各个通道上的综合信息结果
- 多个卷积核
Model Architecture
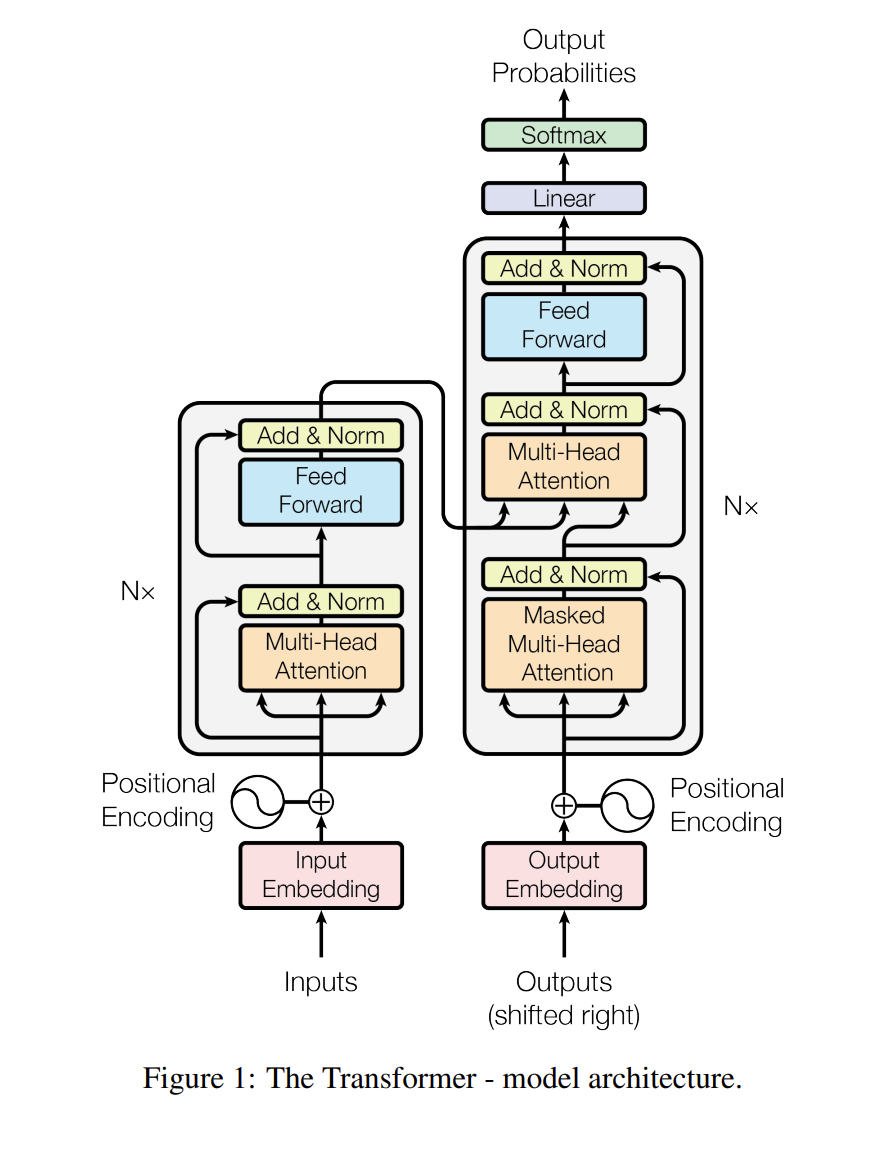
模型组成
左半边是编码器,右半边是解码器
Encoder:
一个类似于resnet方式连接的 Multi-Head Attention, 加上一个MLP,经过 norm 输出到 右半边
只有两个参数需要调
- N (文章中默认为6)
- d.model = 512 (因为残差要求输入和输出是一样的大小,这里为了方便,将每层的输出设置为512
batch norm & Layer norm
为什么变长的应用中不使用 batch norm?
本质上是特征提取的方向不同
Decoder
在预测t时刻的输出时,不应该看到t时刻之后的输出。这里通过 Masked Multi-Head Attention 实现。
https://www.zhihu.com/question/325839123
模型解释
首先输入到 Multi-Head Attention 有三个输入分别是 q,k,v.
但这里是一根线过来复制成了三份,意思是同样一个东西既作为q,又作为k,又作为v
Multi-Head Attention解释
参考 https://zh.d2l.ai/chapter_attention-mechanisms/multihead-attention.html
当给定相同的查询、键和值的集合时, 我们希望模型可以基于相同的注意力机制学习到不同的行为, 然后将不同的行为作为知识组合起来, 捕获序列内各种范围的依赖关系 (例如,短距离依赖和长距离依赖关系)。 因此,允许注意力机制组合使用查询、键和值的不同 子空间表示(representation subspaces)可能是有益的。
为此,与其只使用单独一个注意力汇聚, 我们可以用独立学习得到的ℎ组不同的 线性投影(linear projections)来变换查询、键和值。 然后,这ℎ组变换后的查询、键和值将并行地送到注意力汇聚中。 最后,将这ℎ个注意力汇聚的输出拼接在一起, 并且通过另一个可以学习的线性投影进行变换, 以产生最终输出。 这种设计被称为多头注意力(multihead attention) (Vaswani et al., 2017)。 对于ℎ个注意力汇聚输出,每一个注意力汇聚都被称作一个头(head)。 图10.5.1 展示了使用全连接层来实现可学习的线性变换的多头注意力。
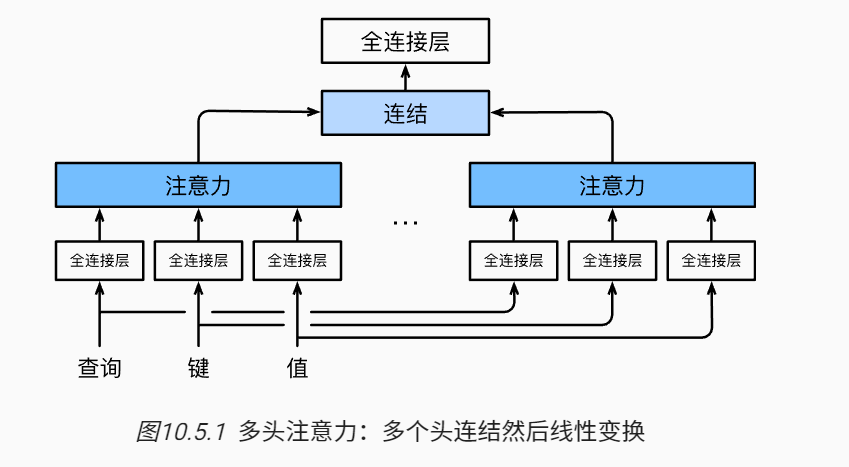
原文的解释:

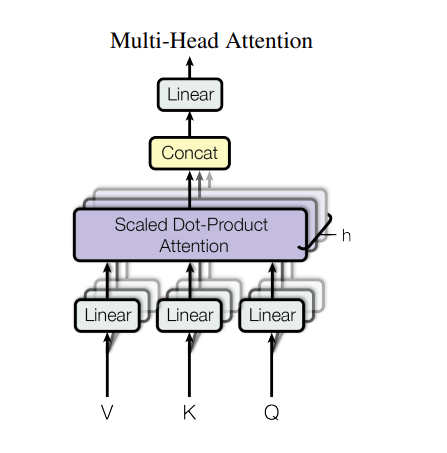

说白了就是对 Q,K,V 做投影,再做注意力机制,然后再 concat 起来
基于这种设计,每个头都可能会关注输入的不同部分, 可以表示比简单加权平均值更复杂的函数。
这里我们关注一下投影的写法
先给qkv上一个全连接层,同一维度为num_hiddens
1 | self.W_q = tf.keras.layers.Dense(num_hiddens, use_bias=bias) |
1 | queries = transpose_qkv(self.W_q(queries), self.num_heads) |
然后reshape一下
1 | #@save |