一篇文章带你读懂h5文件格式
起因
学长发给我的h5文件不会处理 直接寄
what is h5
H5⽂件是层次数据格式第5代的版本(Hierarchical Data Format,HDF5),它是⽤于存储科学数据的⼀种⽂件格式和库⽂件。由美国超级
计算中⼼与应⽤中⼼研发的⽂件格式,⽤以存储和组织⼤规模数据。
h5⽂件为⼀个存放数据的容器,包括group名称和datasets,group名称为key,datasets为value,⽂件结构如下图:

how to write/read form a h5 file
pandas中的HDFStore()用于生成管理HDF5文件IO操作的对象,其主要参数如下:
path:字符型输入,用于指定h5文件的名称(不在当前工作目录时需要带上完整路径信息)mode:用于指定IO操作的模式,与Python内建的open()中的参数一致,默认为’a’,即当指定文件已存在时不影响原有数据写入,指定文件不存在时则新建文件;’r’,只读模式;’w’,创建新文件(会覆盖同名旧文件);’r+’,与’a’作用相似,但要求文件必须已经存在;complevel:int型,用于控制h5文件的压缩水平,取值范围在0-9之间,越大则文件的压缩程度越大,占用的空间越小,但相对应的在读取文件时需要付出更多解压缩的时间成本,默认为0,代表不压缩
write
下面我们创建一个HDF5 IO对象store:
1 | import pandas as pd |
输出:
1 | Closing remaining open files:demo.h5...done |
可以看到store对象属于pandas的io类,通过上面的语句我们已经成功的初始化名为demo.h5的的文件,本地也相应的出现了如下的文件:

接下来我们创建pandas中不同的两种对象,并将它们共同保存到store中,首先创建series对象:
1 | import numpy as np |
输出:
1 | a 1.524228 |
接着我们创建一个dataframe对象:
1 | #创建一个dataframe对象 |
输出:
1 | A B C |
第一种方式利用键值对将不同的数据存入store对象中 这里为了代码简洁使用了元组赋值法:
1 | store['s'],store['df'] = s,df |
第二种方式利用store对象的put()方法,其主要参数如下:
key:指定h5文件中待写入数据的key
value:指定与key对应的待写入的数据
format:字符型输入,用于指定写出的模式,’fixed’对应的模式速度快,但是不支持追加也不支持检索;’table’对应的模式以表格的模式写出,速度稍慢,但是支持直接通过store对象进行追加和表格查询操作
使用put()方法将数据存入store对象中:
1 | store.put(key='s',value=s);store.put(key='df',value=df) |
既然是键值对的格式,那么可以查看store的items属性(注意这里store对象只有items和keys属性,没有values属性):
1 | store.items() |
1 | store.keys() |
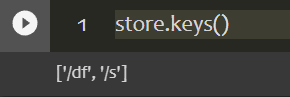
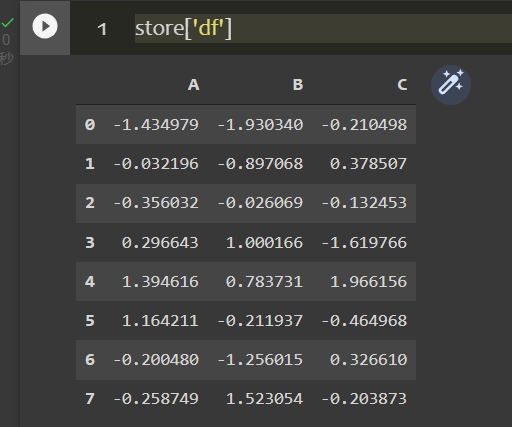
调用store对象中的数据直接用对应的键名来索引即可:
1 | store['df'] |
删除store对象中指定数据的方法有两种,一是使用remove()方法,传入要删除数据对应的键:
1 | store.remove('s') |
二是使用Python中的关键词del来删除指定数据:
1 | del store['s'] |
这时若想将当前的store对象持久化到本地,只需要利用close()方法关闭store对象即可:
1 | store.close() |
这时本地的h5文件也相应的存储进store对象关闭前包含的文件
除了通过定义一个确切的store对象的方式,还可以从pandas中的数据结构直接导出到本地h5文件中:
1 | #创建新的数据框 |
read
在pandas中读入HDF5文件的方式主要有两种,一是通过上一节中类似的方式创建与本地h5文件连接的IO对象,接着使用键索引或者store对象的get()方法传入要提取数据的key来读入指定数据:
1 | store = pd.HDFStore('demo.h5') |
这两种方式都能顺利读取键对应的数据。
第二种读入h5格式文件中数据的方法是pandas中的read_hdf(),其主要参数如下:
path_or_buf:传入指定h5文件的名称
key:要提取数据的键
需要注意的是利用read_hdf()读取h5文件时对应文件不可以同时存在其他未关闭的IO对象,否则会报错