attention相关知识总结(seq2seq、Encoder-Decoder等)
学学 温故而知新 于2023.3.25 修改
要详细了解的model
| model | achieved |
|---|---|
| TCN | |
| attention Mechanism | |
| dynamic graph attention networks |
Attention
起源:获取更多所需要关注目标的细节信息,而抑制其他无用信息
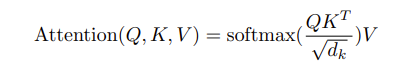
q query
v value
K key
看了一个视频,他是这么解释的 key 可以理解为查询后计算得到的相似性 value 是价值
所以 用相似性 x 价值 来衡量注意力
softmax 作用 转化为权重
除以 dk 论文里有解释 是因为处理梯度上的问题


Attention Mechanism
RNN的缺陷
在没有Transformer以前,大家做神经机器翻译用的最多的是基于RNN的Encoder-Decoder模型:
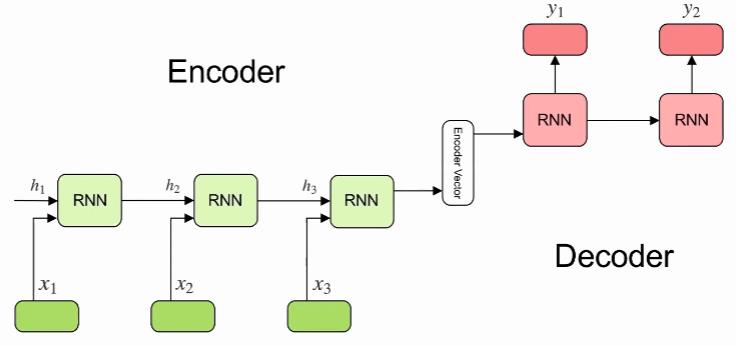
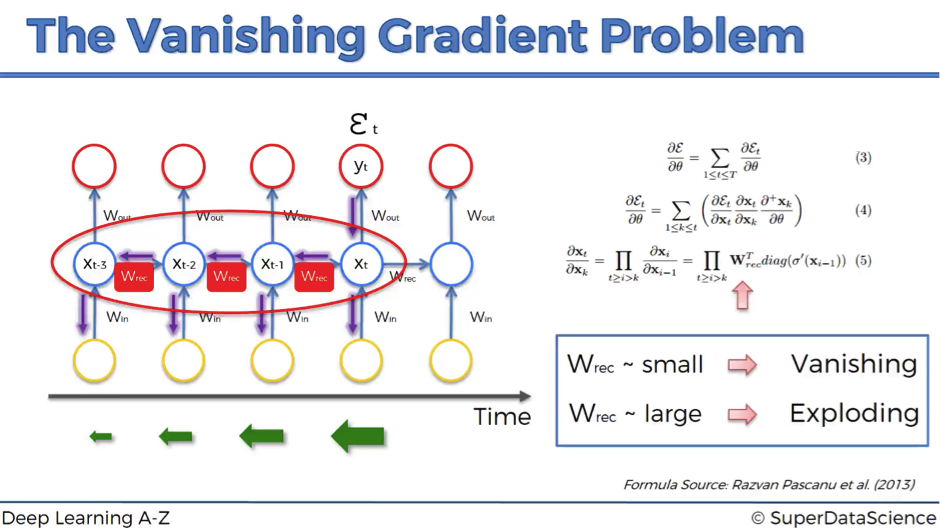
Encoder-Decoder模型当然很成功,在2018年以前用它是用的很多的。而且也有很强的能力。但是RNN天生有缺陷,只要是RNN,就会有梯度消失问题,核心原因是有递归的方式,作用在同一个权值矩阵上,使得如果这个矩阵满足条件的话,其最大的特征值要是小于1的话,那就一定会出现梯度消失问题。后来的LSTM和GRU也仅仅能缓解这个问题
Transformer为何优于RNN
Transformer中抛弃了传统的CNN和RNN,整个网络结构完全是由Attention机制组成。 作者采用Attention机制的原因是考虑到RNN(或者LSTM,GRU等)的计算限制为是顺序的,也就是说RNN相关算法只能从左向右依次计算或者从右向左依次计算,这种机制带来了两个问题:
- 时间片
t的计算依赖t−1时刻的计算结果,这样限制了模型的并行能力 - 顺序计算的过程中信息会丢失,尽管LSTM等门机制的结构一定程度上缓解了长期依赖的问题,但是对于特别长期的依赖现象,LSTM依旧无能为力。
Transformer的提出解决了上面两个问题:
- 首先它使用了Attention机制,将序列中的任意两个位置之间的距离缩小为一个常量;
- 其次它不是类似RNN的顺序结构,因此具有更好的并行性,符合现有的GPU框架。
Transformer模型架构
Transformer模型在论文《Attention Is All You Need》中被提出,利用Attention,去掉RNN。这篇论文的题目想说的是:你只需要用到Attention机制,完全不需要再用到RNN,就能解决很多问题。Transformer没有用到RNN,而且它的效果很好。
Transformer模型总体的样子如下图所示:总体来说,还是和Encoder-Decoder模型有些相似,左边是Encoder部分,右边是Decoder部分。
![]()
Encoder:输入是单词的Embedding,再加上位置编码,然后进入一个统一的结构,这个结构可以循环很多次(N次),也就是说有很多层(N层)。每一层又可以分成Attention层和全连接层,再额外加了一些处理,比如Skip Connection,做跳跃连接,然后还加了Normalization层。其实它本身的模型还是很简单的。
Decoder:第一次输入是前缀信息,之后的就是上一次产出的Embedding,加入位置编码,然后进入一个可以重复很多次的模块。该模块可以分成三块来看,第一块也是Attention层,第二块是cross Attention,不是Self-Attention,第三块是全连接层。也用了跳跃连接和Normalization。
输出:最后的输出要通过Linear层(全连接层),再通过softmax做预测。
再换用另一种简单的方式来解释Transformer的网络结构。
![]()
需要注意的上图的Decoder的第一个输入,就是output的前缀信息。
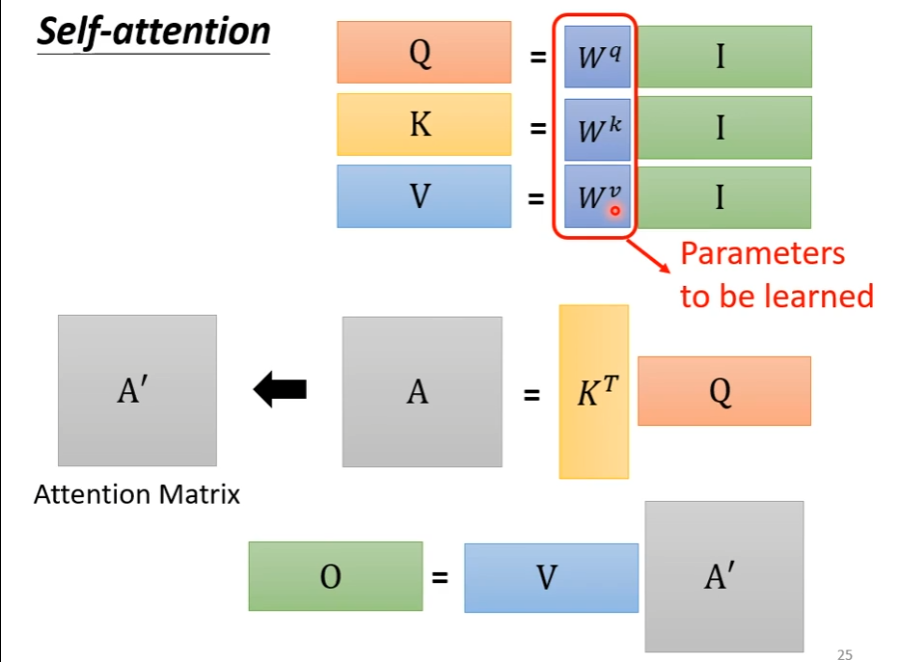
self-attention
Attention和self-attention的区别
以Encoder-Decoder框架为例,输入Source和输出Target内容是不一样的,比如对于英-中机器翻译来说,Source是英文句子,Target是对应的翻译出的中文句子,Attention发生在Target的元素Query和Source中的所有元素之间。
Self Attention,指的不是Target和Source之间的Attention机制,而是Source内部元素之间或者Target内部元素之间发生的Attention机制,也可以理解为Target=Source这种特殊情况下的Attention。
两者具体计算过程是一样的,只是计算对象发生了变化而已。
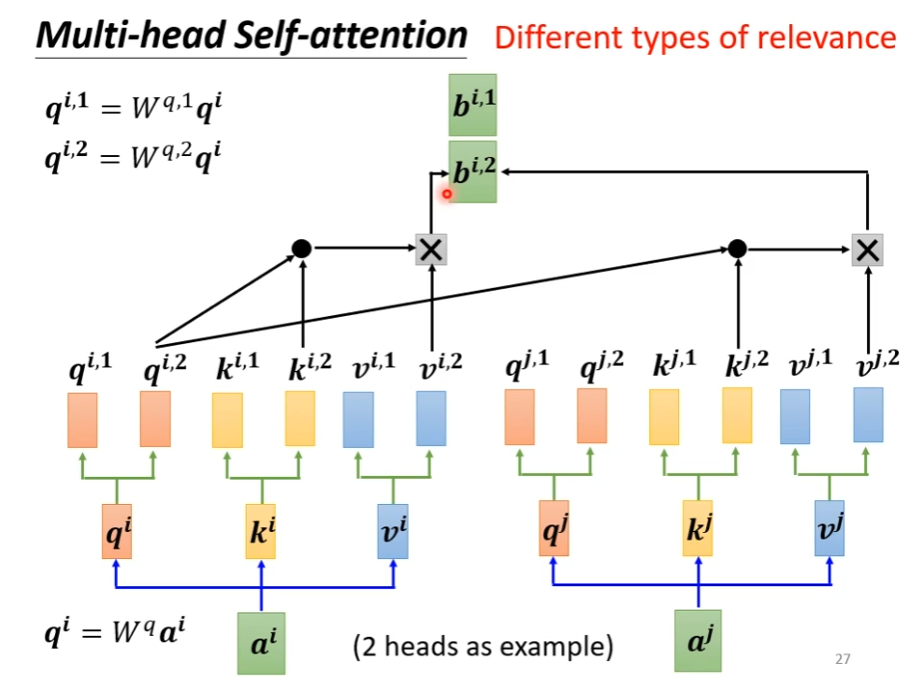
下图是李宏毅老师的视频截图
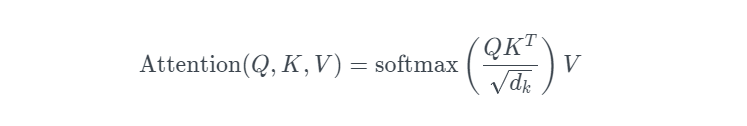

multi-headed Attention
一些感悟
- 永远要善于分享自己的想法 并乐于让别人来给出评价 不能故步自封
pytorch实现
https://wmathor.com/index.php/archives/1451/
代码部分解释
通过代码简介什么是attention, self-attention, multi-head attention以及transformer_哔哩哔哩_bilibili
attention
1 | import torch |
multi-Head attention
1 | ## How to build multi-head attention using Pytorch? |
transformer
1 | ## How to build multi-head attention using Pytorch? |
reference
https://www.youtube.com/watch?v=9_1cEtimRNE (有空看看)
https://zhuanlan.zhihu.com/p/186987950 动态图注意力机制
https://blog.floydhub.com/attention-mechanism/
http://xtf615.com/2019/01/06/attention/
https://mp.weixin.qq.com/s/lUqpCae3TPkZlgT7gUatpg
https://nlp.seas.harvard.edu/2018/04/03/attention.html#encoder