Python-security
写一篇文章来记录一下与python相关的安全知识 由于这方面的问题比较少 所以打算快速的过一遍 然后就去研究Java安全了
题纲
1 | 1.内置危险函数 |
一些基础知识
Command Execution Libraries
1 | os.system("ls") |
Remember that the open and read functions can be useful to read files inside the python sandbox and to write some code that you could execute to bypass the sandbox.
还要补充一点,关于python3.6引入的一个字符串修饰符f,即f-strings,这个比较有意思了,能实现的效果基本和format差不太多,同样可以用来进行命令执行
1 | f"{__import__('os').system('ls')}" |
这也会是一个可能能够用上的点。
pickle反序列化
pickle简介

- 与PHP类似,python也有序列化功能以长期储存内存中的数据。pickle是python下的序列化与反序列化包。
- python有另一个更原始的序列化包marshal,现在开发时一般使用pickle。
- 与json相比,pickle以二进制储存,不易人工阅读;json可以跨语言,而pickle是Python专用的;pickle能表示python几乎所有的类型(包括自定义类型),json只能表示一部分内置类型且不能表示自定义类型。
- pickle实际上可以看作一种独立的语言,通过对opcode的更改编写可以执行python代码、覆盖变量等操作。直接编写的opcode灵活性比使用pickle序列化生成的代码更高,有的代码不能通过pickle序列化得到(pickle解析能力大于pickle生成能力)。
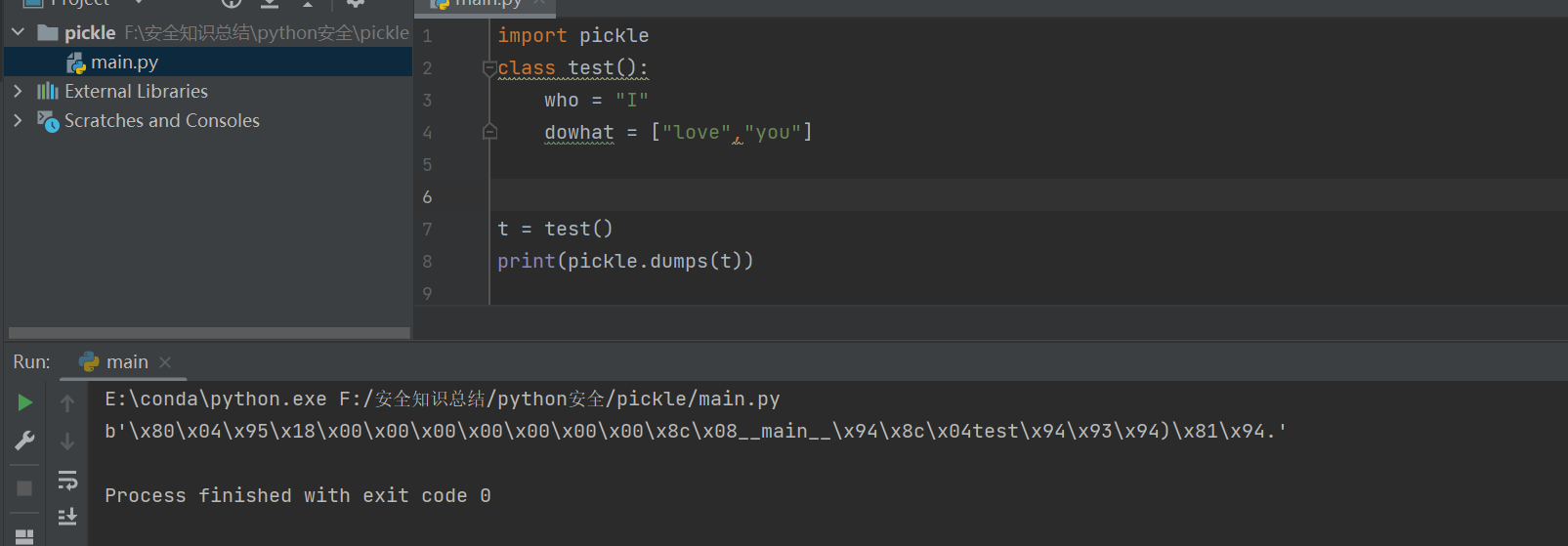
可序列化的对象
None、True和False- 整数、浮点数、复数
- str、byte、bytearray
- 只包含可打包对象的集合,包括 tuple、list、set 和 dict
- 定义在模块顶层的函数(使用
def定义,lambda函数则不可以) - 定义在模块顶层的内置函数
- 定义在模块顶层的类
- 某些类实例,这些类的
__dict__属性值或__getstate__()函数的返回值可以被打包(详情参阅 打包类实例 这一段)。
object.__reduce__() 函数
该接口当前定义如下。__reduce__() 方法不带任何参数,并且应返回字符串或最好返回一个元组(返回的对象通常称为“reduce 值”)。
如果返回字符串,该字符串会被当做一个全局变量的名称。它应该是对象相对于其模块的本地名称,pickle 模块会搜索模块命名空间来确定对象所属的模块。这种行为常在单例模式使用。
当返回的是一个元组时,它的长度必须在二至五项之间。 可选项可以被省略或将值设为 None。 每项的语义分别如下所示:
- 一个可调用对象,该对象会在创建对象的最初版本时调用。
- 可调用对象的参数,是一个元组。如果可调用对象不接受参数,必须提供一个空元组。
- 可选元素,用于表示对象的状态,将被传给前述的
__setstate__()方法。 如果对象没有此方法,则这个元素必须是字典类型,并会被添加至__dict__属性中。 - 可选元素,一个返回连续项的迭代器(而不是序列)。这些项会被
obj.append(item)逐个加入对象,或被obj.extend(list_of_items)批量加入对象。这个元素主要用于 list 的子类,也可以用于那些正确实现了append()和extend()方法的类。(具体是使用append()还是extend()取决于 pickle 协议版本以及待插入元素的项数,所以这两个方法必须同时被类支持。) - 可选元素,一个返回连续键值对的迭代器(而不是序列)。这些键值对将会以
obj[key] = value的方式存储于对象中。该元素主要用于 dict 子类,也可以用于那些实现了__setitem__()的类。
1 | #encoding: utf-8 |

用pickletools可以直观的解析
1 | import pickletools |
1 | 0: \x80 PROTO 4 |
opcode简介
版本
当前用于 pickling 的协议共有 5 种。使用的协议版本越高,读取生成的 pickle 所需的 Python 版本就要越新。
- v0 版协议是原始的 “人类可读” 协议,并且向后兼容早期版本的 Python。
- v1 版协议是较早的二进制格式,它也与早期版本的 Python 兼容。
- v2 版协议是在 Python 2.3 中引入的。它为存储 new-style class 提供了更高效的机制。欲了解有关第 2 版协议带来的改进,请参阅 PEP 307。
- v3 版协议添加于 Python 3.0。它具有对 bytes 对象的显式支持,且无法被 Python 2.x 打开。这是目前默认使用的协议,也是在要求与其他 Python 3 版本兼容时的推荐协议。
- v4 版协议添加于 Python 3.4。它支持存储非常大的对象,能存储更多种类的对象,还包括一些针对数据格式的优化。有关第 4 版协议带来改进的信息,请参阅 PEP 3154。
1 | import pickle |
输出
1 |
|
如何手写opcode
- 在CTF中,很多时候需要一次执行多个函数或一次进行多个指令,此时就不能光用
__reduce__来解决问题(reduce一次只能执行一个函数,当exec被禁用时,就不能一次执行多条指令了),而需要手动拼接或构造opcode了。手写opcode是pickle反序列化比较难的地方。 - 在这里可以体会到为何pickle是一种语言,直接编写的opcode灵活性比使用pickle序列化生成的代码更高,只要符合pickle语法,就可以进行变量覆盖、函数执行等操作。
- pickle协议是向前兼容的。0号版本的字符串可以直接交给
pickle.loads()。手动编写时,一般选用版本0的opcode。
对应实现 cpython/pickle.py at main · python/cpython (github.com)
| opcode | 描述 | 具体写法 | 栈上的变化 | memo上的变化 |
|---|---|---|---|---|
| c | 获取一个全局对象或import一个模块(注:会调用import语句,能够引入新的包) | c[module]\n[instance]\n | 获得的对象入栈 | 无 |
| o | 寻找栈中的上一个MARK,以之间的第一个数据(必须为函数)为callable,第二个到第n个数据为参数,执行该函数(或实例化一个对象) | o | 这个过程中涉及到的数据都出栈,函数的返回值(或生成的对象)入栈 | 无 |
| i | 相当于c和o的组合,先获取一个全局函数,然后寻找栈中的上一个MARK,并组合之间的数据为元组,以该元组为参数执行全局函数(或实例化一个对象) | i[module]\n[callable]\n | 这个过程中涉及到的数据都出栈,函数返回值(或生成的对象)入栈 | 无 |
| N | 实例化一个None | N | 获得的对象入栈 | 无 |
| S | 实例化一个字符串对象 | S’xxx’\n(也可以使用双引号、'等python字符串形式) | 获得的对象入栈 | 无 |
| V | 实例化一个UNICODE字符串对象 | Vxxx\n | 获得的对象入栈 | 无 |
| I | 实例化一个int对象 | Ixxx\n | 获得的对象入栈 | 无 |
| F | 实例化一个float对象 | Fx.x\n | 获得的对象入栈 | 无 |
| R | 选择栈上的第一个对象作为函数、第二个对象作为参数(第二个对象必须为元组),然后调用该函数 | R | 函数和参数出栈,函数的返回值入栈 | 无 |
| . | 程序结束,栈顶的一个元素作为pickle.loads()的返回值 | . | 无 | 无 |
| ( | 向栈中压入一个MARK标记 | ( | MARK标记入栈 | 无 |
| t | 寻找栈中的上一个MARK,并组合之间的数据为元组 | t | MARK标记以及被组合的数据出栈,获得的对象入栈 | 无 |
| ) | 向栈中直接压入一个空元组 | ) | 空元组入栈 | 无 |
| l | 寻找栈中的上一个MARK,并组合之间的数据为列表 | l | MARK标记以及被组合的数据出栈,获得的对象入栈 | 无 |
| ] | 向栈中直接压入一个空列表 | ] | 空列表入栈 | 无 |
| d | 寻找栈中的上一个MARK,并组合之间的数据为字典(数据必须有偶数个,即呈key-value对) | d | MARK标记以及被组合的数据出栈,获得的对象入栈 | 无 |
| } | 向栈中直接压入一个空字典 | } | 空字典入栈 | 无 |
| p | 将栈顶对象储存至memo_n | pn\n | 无 | 对象被储存 |
| g | 将memo_n的对象压栈 | gn\n | 对象被压栈 | 无 |
| 0 | 丢弃栈顶对象 | 0 | 栈顶对象被丢弃 | 无 |
| b | 使用栈中的第一个元素(储存多个属性名: 属性值的字典)对第二个元素(对象实例)进行属性设置 | b | 栈上第一个元素出栈 | 无 |
| s | 将栈的第一个和第二个对象作为key-value对,添加或更新到栈的第三个对象(必须为列表或字典,列表以数字作为key)中 | s | 第一、二个元素出栈,第三个元素(列表或字典)添加新值或被更新 | 无 |
| u | 寻找栈中的上一个MARK,组合之间的数据(数据必须有偶数个,即呈key-value对)并全部添加或更新到该MARK之前的一个元素(必须为字典)中 | u | MARK标记以及被组合的数据出栈,字典被更新 | 无 |
| a | 将栈的第一个元素append到第二个元素(列表)中 | a | 栈顶元素出栈,第二个元素(列表)被更新 | 无 |
| e | 寻找栈中的上一个MARK,组合之间的数据并extends到该MARK之前的一个元素(必须为列表)中 | e | MARK标记以及被组合的数据出栈,列表被更新 | 无 |
BH_US_11_Slaviero_Sour_Pickles.pdf (sensepost.com)
从学长的一篇文章中学习
Python pickle 反序列化实例分析 - 安全客,安全资讯平台 (anquanke.com)
基本模式:
1 | c<module> |
先来看一个例子
1 | cos |
源码分析
这里记录一下一个小trick 怎么找python源码
我是直接Ctrl + B
还学习到一种做法
1 | import pickle |
最后都调用了1 _Unpickler
CTF
高校战疫情 webtmp
1 |
|
1 | def restricted_loads(s): |
[CISCN2019 华北赛区 Day1 Web2]ikun
reference
https://book.hacktricks.xyz/generic-methodologies-and-resources/python/bypass-python-sandboxes