result = [] all_data = pd.read_csv(file,encoding="gbk",names=["data"])["data"] for words in all_data: c_words = jieba.lcut(words) result.append([word for word in c_words if word notin stop_words]) return result
获取上面三个值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
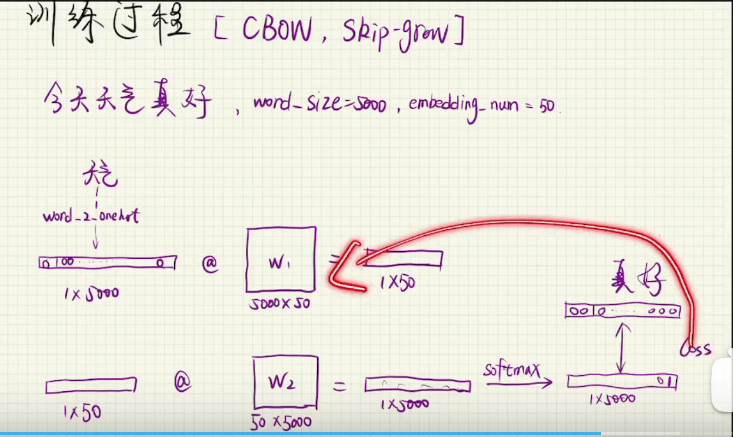
defget_dict(data): # 重复词过滤 index_2_word = [] for words in data: for word in words: if word notin index_2_word: index_2_word.append(word)
word_2_index = {word:index for index,word inenumerate(index_2_word)} word_size = len(word_2_index)
word_2_onehot = {} for word,index in word_2_index.items(): one_hot = np.zeros((1,word_size)) one_hot[0,index] = 1 word_2_onehot[word] = one_hot