run哥带你手写KNN
一个老师布置的任务 玩玩
既然要手写KNN,那么首先我们不能用框架,其次尽量少的参考别人的代码
首先要找一个数据集来用 找哪个好呢?
这时我想大家可能猜到了 – 鸢尾花 okk
okk let‘s do it!
KNN算法学习
首先来了解一下三种距离
闵可夫斯基距离,欧式距离,曼哈顿距离
懒得写了 自己查吧
加载数据集
Iris数据集是常用的分类实验数据集,由Fisher, 1936收集整理。Iris也称鸢尾花卉数据集,是一类多重变量分析的数据集。数据集包含150个数据样本,分为3类,每类50个数据,每个数据包含4个属性。可通过花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性预测鸢尾花卉属于(Setosa,Versicolour,Virginica)三个种类中的哪一类。
加载数据
1 | from sklearn.datasets import load_iris |
查看数据
1 | iris = load_iris() |
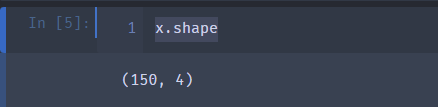
数据集划分
1 | from sklearn.model_selection import train_test_split |
看一下成功没
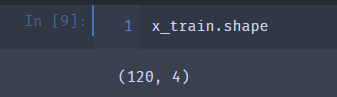
okk 我们已经处理好了了数据集
接下来就是算法的实现了
算法实现
核心就是一个距离的计算
首先来确定一个K 这里我们选 7 这强大的数字
然后就是
计算待预测点与已知点之间的关系 这里我们选择较为简单的欧氏距离来计算
将计算的结果进行从小到大排序,取前K个点,再将待预测点归类为多数的那一个类别,这便是对于未知点的类别预测结果了。
由于我们有四个特征 所以应该计算的是四维的距离
先把计算距离的代码给搓出来 也就是计算x_test 中每组特征与x_train 中每组特征的距离 然后取前7组
这里要用到numpy
计算方法可参考 (159条消息) 如何使用NumPy计算欧几里得距离?_asdfgh0077的博客-CSDN博客_numpy 欧式距离
这里我们随便选择一种即可
较为简陋的一次尝试
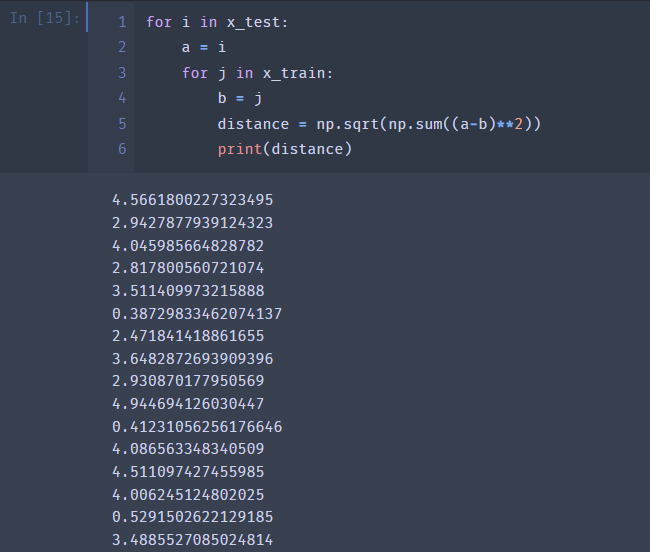
ok 接下来让我们来选择前7个来判断他到底属于那一类
我这里十分详细了 十分照顾对python不熟练的童鞋
https://blog.csdn.net/qq_45619551/article/details/122884071
然后去 y_train 中找其对应的 label
简单的改了一下 发现已经给算出来了

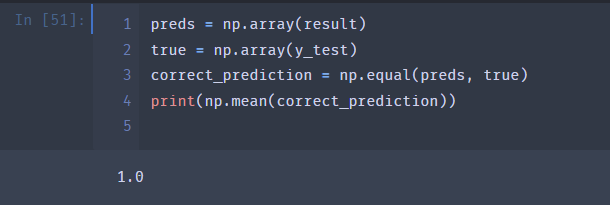
然后我们简单计算一下准确率
我超 全队 爽