run哥带你手撕k-means算法
run哥带你学AI第二期 今天来讲讲k-means算法
通过上期的 KNN 算法 我们这学期就可以进展地很快了
首先来看一下 k-means 算法如何应用
算法步骤
step1
确定聚类个数,确定聚类中心,确定距离计算公式
对于K-Means算法,首先要注意的是k值的选择,一般来说,我们会根据对数据的先验经验选择一个合适的k值,如果没有什么先验知识,则可以通过交叉验证选择一个合适的k值。
在确定了k的个数后,我们需要选择k个初始化的质心(随机)。由于我们是启发式方法,k个初始化的质心的位置选择对最后的聚类结果和运行时间都有很大的影响,因此需要选择合适的k个质心,最好这些质心不能太近。
step2
计算每个点和聚类中心的距离,进行归类
step3
计算当前类簇的中心,更新聚类中心的位置(质心法)
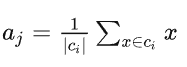
step4
重复上面 2,3 两步操作,直到达到某个中止条件(迭代次数、最小误差变化等)
优缺点
优点
- 容易理解,聚类效果不错,虽然是局部最优, 但往往局部最优就够了;
- 处理大数据集的时候,该算法可以保证较好的伸缩性;
- 当簇近似高斯分布的时候,效果非常不错;
- 算法复杂度低。
缺点
- K 值需要人为设定,不同 K 值得到的结果不一样;
- 对初始的簇中心敏感,不同选取方式会得到不同结果;
- 对异常值敏感;
- 样本只能归为一类,不适合多分类任务;
- 不适合太离散的分类、样本类别不平衡的分类、非凸形状的分类。
附加知识
证明这玩意
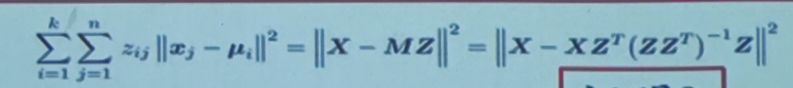
https://medium.com/@1993jayant/k-means-clustering-as-a-matrix-factorization-problem-ce1de56c6ec6