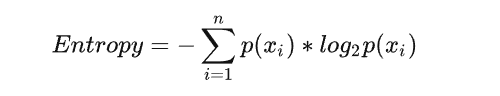from collections import Counter from math import log import numpy as np
# 用一个二维数组来存? # x_train , y_train withopen("F://机器学习/run-shousi/隐形眼镜/lenses.data","r") as lenses: data = [i.strip().split() for i in lenses.readlines()] # 然后分为 x_train , y_train x_train = [j[1:5] for j in data] y_train = [k[-1] for k in data] dataset = [p[1:] for p in data]
defcalc_shannon(data): l = len(data) c = dict(Counter(data)) # 计算总体的熵 shang = [-c[t]/l*log((c[t]/l),2) for t in c ] returnsum(shang)
Y_Info = calc_shannon(y_train)
defcalc_feature_shannon(x_train,y_train):
bastinfogain = 0 bestfeature = 0
for i inrange(len(x_train[0])): Info = 0 # print(x_train[:,i]) # print(dict(Counter(x_train[:,i]))) feature = x_train[:,i] c = dict(Counter(x_train[:,i]))
# 现在知道了 for key in c: # print(k) l = [] for j inrange(0,len(feature)): if feature[j] == key: l.append(y_train[j]) # 计算l的熵
Info += c[key]/len(feature) * calc_shannon(l) infogain = Y_Info - Info if infogain > bastinfogain: bastinfogain = infogain bestfeature = i # 返回各特征的信息熵 return bastinfogain,bestfeature
defsplitDataset(x_train,axis,value): res = [] for i in x_train: # print(type(i[0])) numpy.str_ if i[axis] == value: res.append(i)