defforward(self, x): # Initializing hidden state for first input with zeros h0 = torch.zeros(self.layer_dim, x.size(0), self.hidden_dim).requires_grad_()
# Forward propagation by passing in the input and hidden state into the model out, h0 = self.rnn(x, h0.detach())
# Reshaping the outputs in the shape of (batch_size, seq_length, hidden_size) # so that it can fit into the fully connected layer out = out[:, -1, :]
# Convert the final state to our desired output shape (batch_size, output_dim) out = self.fc(out) return out
defforward(self, x): # Initializing hidden state for first input with zeros h0 = torch.zeros(self.layer_dim, x.size(0), self.hidden_dim).requires_grad_()
# Forward propagation by passing in the input and hidden state into the model out, _ = self.gru(x, h0.detach())
# Reshaping the outputs in the shape of (batch_size, seq_length, hidden_size) # so that it can fit into the fully connected layer out = out[:, -1, :]
# Convert the final state to our desired output shape (batch_size, output_dim) out = self.fc(out)
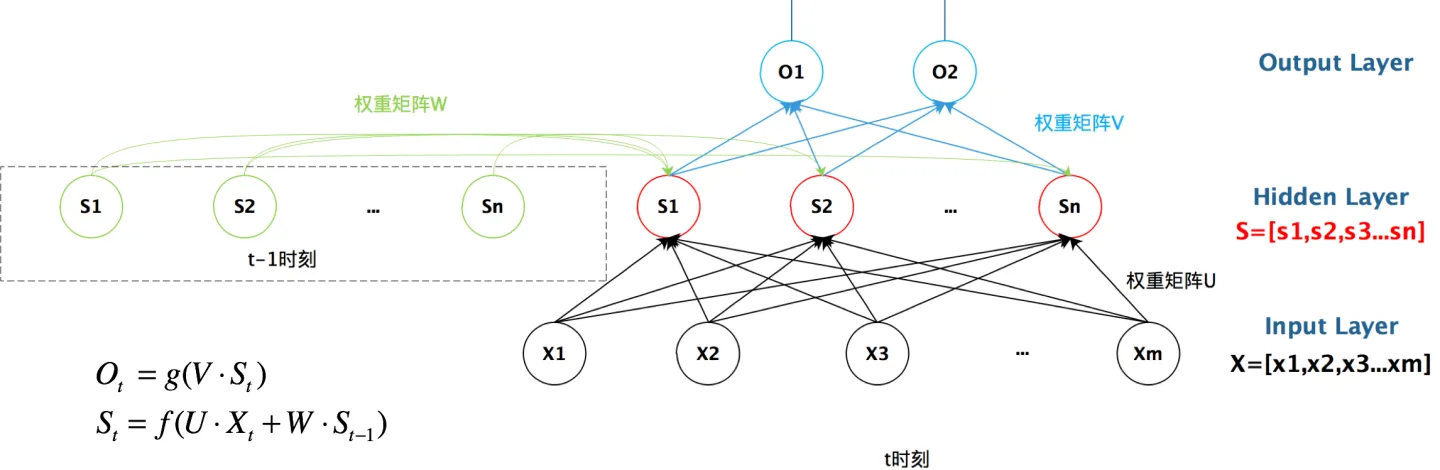
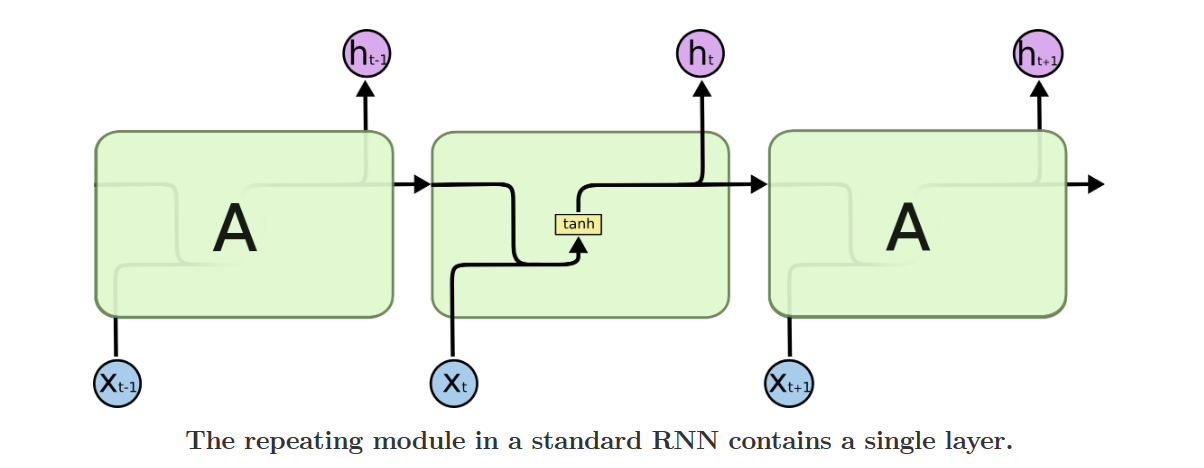

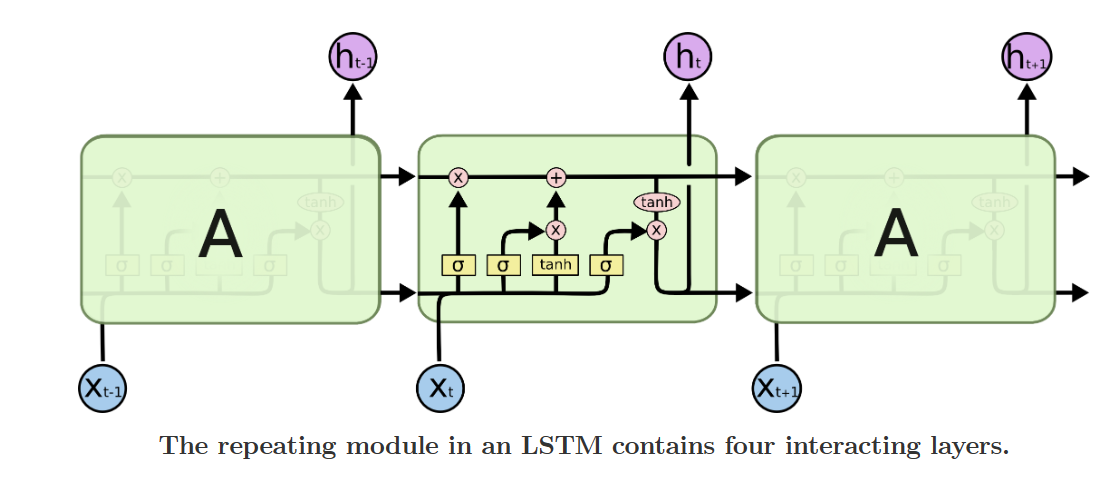
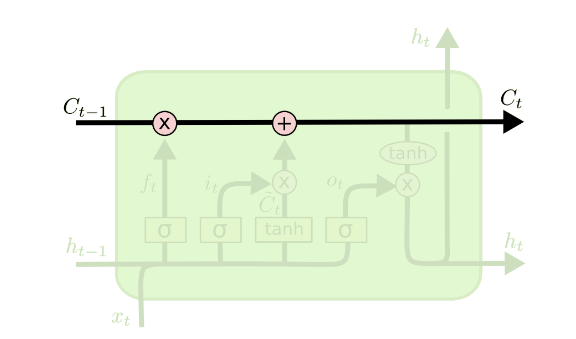
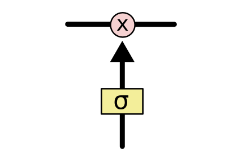
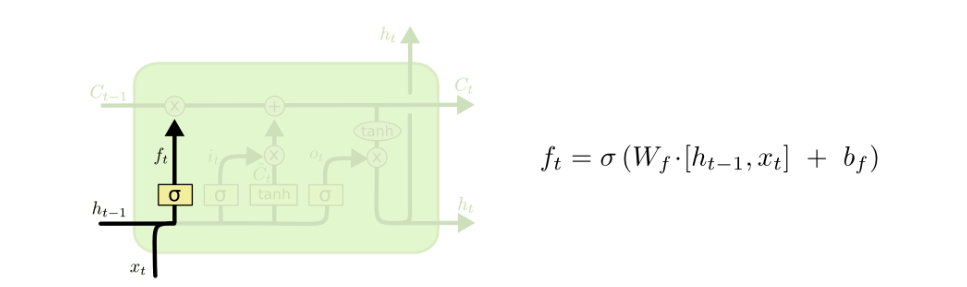
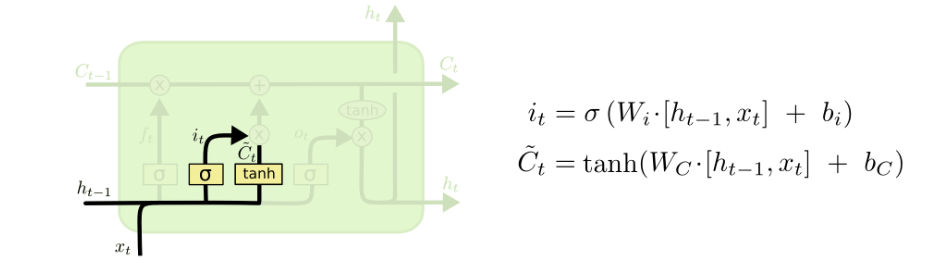
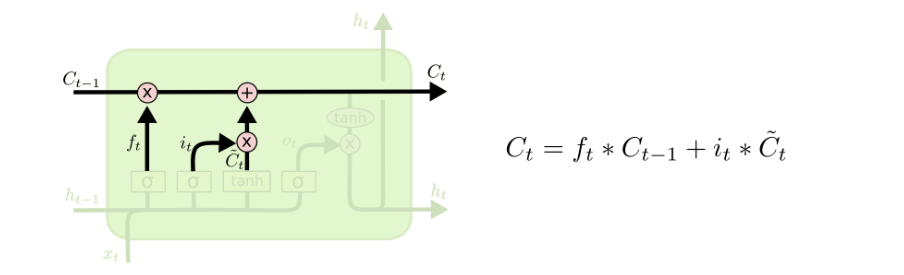
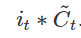 我们接下来要把这个值给更新进去,以得到新的 Ct
我们接下来要把这个值给更新进去,以得到新的 Ct