异常检测实践
learn
时间序列
https://cloud.tencent.com/developer/article/1670322
反欺诈
主要是想借鉴一下 看看有没有什么可以拿来用的
https://www.cs.sjtu.edu.cn/~linghe.kong/AI007/Download/%E7%AC%AC9%E8%AF%BE.pdf
https://welts.xyz/2022/06/23/anomaly_dec/
但要找一个合适的数据集先
目前业界相关场景检测的主要方法为基于规则策略检测。规则策略的基本内容为设定指定时间段内的传输数据阈值,这些阈值和时间段通常是人为设定的常数。规则检测的优点是检测快速,不需要对数据做处理,但是缺点也是显而易见的:
- 规则策略为单纯地进行阈值设定,无法结合历史数据进行分析,容易产生大量的误报,需要运营人员进行排查,造成资源人力浪费。
- 规则策略阈值设定较大时,数据汇集总量较小但异于历史行为的操作会被漏检,从而带来更高的风险。
S-H-ESD算法
异常检测知识
异常检测 (Anomaly Detection ) 针对的是少数、不可预测或 不确定、不符合预期模式的件的识别。
应用场景:
设备运维:黑客攻击监测、服务器运行监测、电力设备发电能力监测
社交网络:利用社交网络数据,发现异常行为的用户(如发帖机器人)或者谣言散播行为
金融欺诈:信用卡欺诈、反洗钱、电信诈骗等
医学场景:异常体征识别、病变区域识别、基因序列异常识别
智慧城市:利用公交卡轨迹数据,识别盗窃行为;利用共享单车骑行轨迹数据,识别违章停车
视频监控:视频场景中的异常事件
数据清洗:一些异常数据可能会导致数据的期望或者方差等严重偏离正常,利用异常检测方法检测出数据中的噪 声通常是数据预处理中很重要的一步
异常的类别
点异常 point anomalies
- 少数个体实例是异常的,大多数个体实例是正常的
- 例:正常人与病人的健康指标
条件异常 conditional anomalies 又称上下文异常
- 在特定情境下个体实例是异常的,在其他情境下都是正常的
- 例:在特定时间下的温度突然上升或下降
群体异常 group anomalies
- 在群体集合中的个体实例出现异常的情况,而该个体实例自身可能不是异常,在入侵或欺诈检测等应用中, 离群点对应于多个数据点的序列,而不是单个数据点
- 例:信用卡突然短时间内不停地消费50元的记录集合作为群体异常子集,但子集中的个体可能与真实消费 记录一样正常
异常检测面临的挑战
未知性
异常与许多未知因素有关,例如,具有未知的突发行为、数据结构和分布的实例。它们直到真正发生时才为 人所知,比如恐怖袭击、诈骗和网络入侵等应用
异常类的异构性
异常是不规则的,一类异常可能表现出与另一类异常完全不同的异常特征。例如,在视频监控中,抢劫、交 通事故和盗窃等异常事件在视觉上有很大差异
类别不均衡
异常通常是罕见的数据实例,而正常实例通常占数据的绝大部分。因此,收集大量标了标签的异常实例是困 难的,甚至是不可能的。这导致在大多数应用程序中无法获得大规模的标记数据

异常检测算法分类
异常检测基于标签的可获得性划分
有监督异常检测
在训练集中的正常实例和异常实例都有标签,这类方法的缺点在于数据标签难以获得或数据不均衡(正常样 本数量远大于异常样本数量)
半监督异常检测
在训练集中只有单一类别(正常实例)的实例,没有异常实例参与训练
无监督异常检测
在训练集中既有正常实例也可能存在异常实例,但假设数据的比例是正常实例远大于异常实例,模型训练过 程中没有标签进行校正
弱监督异常检测
主要是针对异常实例不完全、粗粒度标签、部分实例标签错误等情况进行算法设计
一篇不错的文章
https://zhuanlan.zhihu.com/p/79940809
一个低风险用户的正常业务活动通常没什么可关注的,但是一些高风险人群的正常活动或者低风险账号进行的高危操作则足以值得调查人员关注,更近一步,如果一个高风险用户做了一些高危并且不常出现的动作,那就绝对需要安全人员介入调查了。这里有一个问题,我们如何知道一个用户风险等级是高还是低?这便是UBA及其算法要解决的核心问题,通过建立动态行为基线发现用户偏离正常模式的行为,并根据风险累计的数值判断用户风险级别。综上,构建用户的特征行为矩阵是第一步,也即User-Profile,特征行为矩阵的构建方法五花八门,考虑到HBase支持数据量大,列式存储等特点,我们选择将特征矩阵保存在HBase里。
张三,像其他特权用户一样,利用其账号的权限登录到某一台主机或者服务器,主机登录算法用以检测每个用户经常使用的主机或者服务,DBA通常倾向于登录固定的几台机器,并且都是使用相似的命令,同时销售人员都是使用天兔或者某个XX系统的服务,两者使用方式完全不同。这里张三登录的是一台保存销售数据的服务器,而显然,这与他之前的模式或者与他所在的Peer-Group都是格格不入的。这里我们使用KMeans算法根据用户行为数据的特征矩阵对用户划分Peer-Group,行为模式类似的人群会划分到一个动态群组。
除了动态群组,根据现有的系统权限组进行风险评估同样是一种有效方式,我们从LDAP或者AD获取用户组以及组的成员数,通常规模较小的组比成千上万用户的组风险系数更高。当张三的账号被黑客从普通管理员组提升到超级管理员组的时候,他的账号瞬间进入了一个人烟罕至的群组,这时候他的风险值会瞬间提升。
除了用户登录的机器,登录时间也是行为特征中非常重要的一个环节,基于时间序列的分析方法有很多,这里我们使用KDE(核心概率密度估计)算法来统计和预测用户在某个时间段登录的概率,这种方法可以有效的克服离散数据在模式匹配过程中容易过耦合的问题。比如张三作为一个系统管理员,通常的登录时间是上班时间以及晚饭以后的时间,早上7:30属于正常登录时间,而凌晨0点登录就会被标记为高度反常和可疑。KDE曲线如下图:
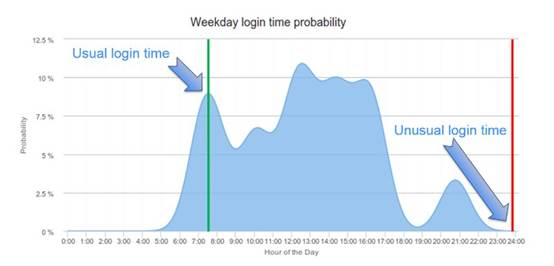
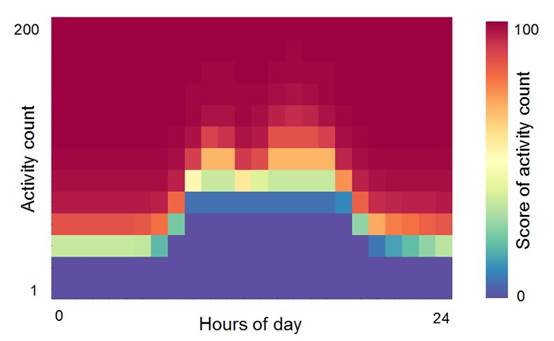
张三登录系统以后进行了一系列的操作,通常一个用户在一段时间内能够产生的操作个数也是一个人的典型特征,User-Profile聚合一个用户在一段时间内产生的所有行为数据的数量,使用KDE重新组织统计数据,并检测这个模式是否发生明显改变。如果这里张三在一小时内接连登录了30+台服务器,而他通常也就登录2、3台,那么这里就与正常的行为有明显的偏移。
基于频繁项集的聚类算法(如Aprior/FP-Growth)在零售行业很早以前就有广泛应用,比如沃尔玛对顾客购买商品的模式发掘发现啤酒和尿布经常一起出售。基于频繁项集的机器学习算法在UBA领域也有广泛应用,比如,张三通常在周末的时候通过SSH协议登录,而在工作日通过RDP协议登录,那么有一天他在周末通过RDP登录就是一个行为模式的偏移。
主成分分析(PCA)是一种应用广泛的降维算法,其在行为数据异常检测的过程中有很好的效果,首先用户行为的特征矩阵往往都有成千上万个维度,如果我们想从海量数据的特征矩阵中找出异常也即离群的点,计算难度会比较大,我们采用PCA对特征进行降维并结合KMeans等聚类算法找出离群点。比如,张三通常会长时间使用前台的服务器,而运维后台服务器的时候比较短,如果他长时间停留在后台服务器上我们的算法会将其潜在的风险值提高。
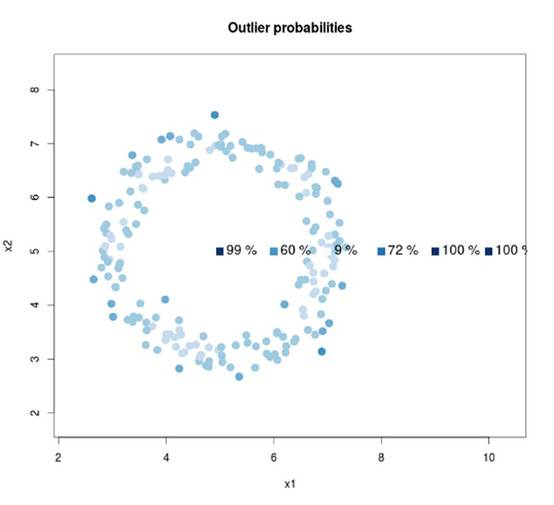
实践
当时实习的最后阶段有随便跑了跑公司的数据
这里简单介绍一下大致的场景,我们公司<200人 数据不完善,加上我们自己是开发者,经常有测试人员会故意测试DLP,外发敏感文件,导致训练基本上是没意义。这里仅仅做一个Demo, 理解一下相关基础算法,已做脱敏处理。
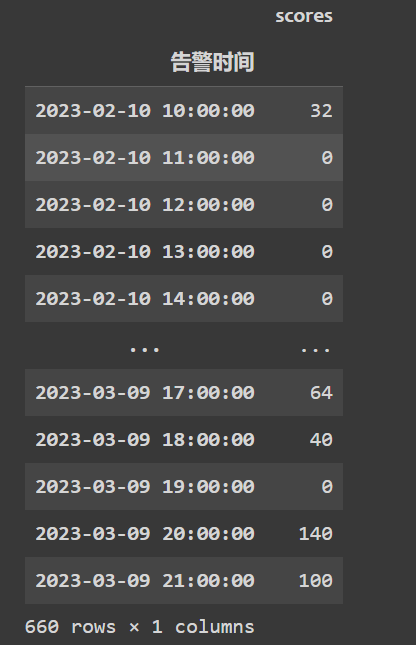
先是读入数据,大概张这样:
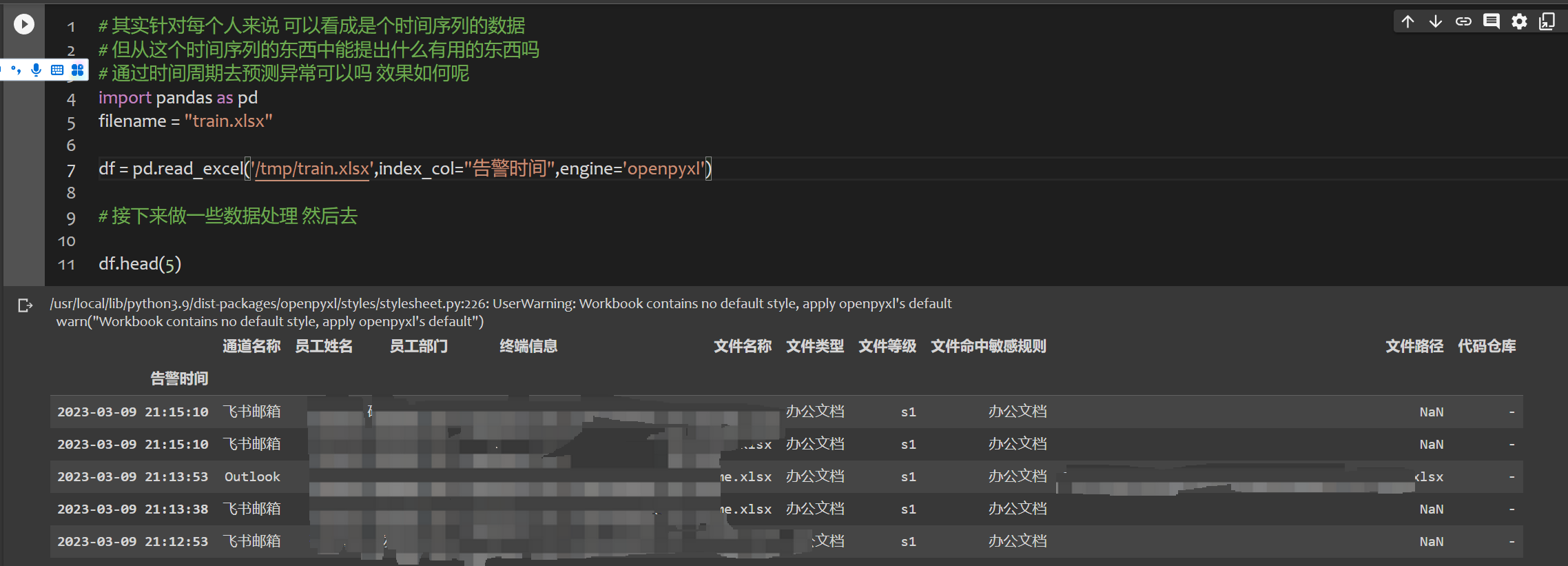
最后我考虑了很久, 决定先用文件登记(敏感登记)来做
对每个文件,我自定义了一套打分规则
1 | scores = [] |
同一时间间隔,以小时为单位
1 | data_hourly = data.resample('1H').sum() |
1 | import numpy as np |
1 | df = data_hourly["scores"] |
最后可视化结果如下
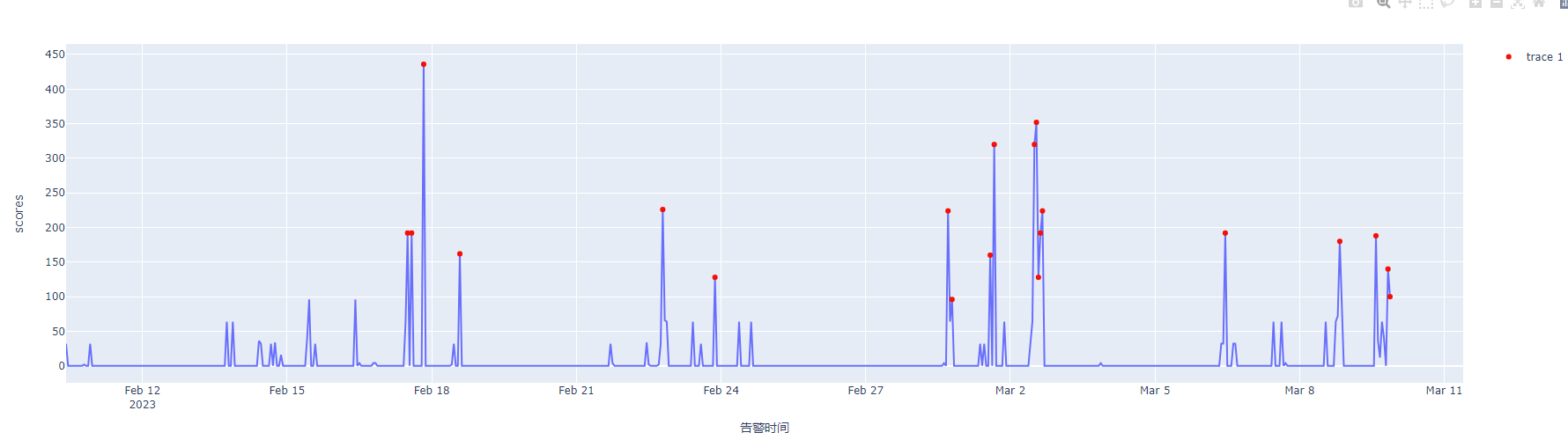
算法
这里用了S-H-ESD算法
https://zhuanlan.zhihu.com/p/265085034
source
PCA
GAN