transformer在时序预测中的有效性探讨
偶然读到一篇令我机器感兴趣的文章,来分享一下
论文地址: https://arxiv.org/pdf/2205.13504.pdf
先聊一下
我们印象中的transformer,有哪些优点 –> 并行性,基于注意力机制,学习的更全面。
那么,它对时序预测真的会起到很好的效果吗?
果然,质疑,才能检验真知。
我们继续看一看。
Abstract
LTSF – long-term time series forecasting 长期时间序列预测
说近期针对LSTF任务,提出了很多基于transformer的解决方案。虽然说,在近几年内表现是越来越好,但是他们团队先质疑。
意思是 transformer 没能从一组组有序的连续点中提取时间上的关系,
作者说 transoformer 主要的能力来源于多头注意力机制,来提取出长序列中的语义相关性。但是 self-attention 是
permutation-invariant and “anti-order” to some extent. 虽然在各种位置编码技术可以一定程度上保留顺序上的信息,但是在这些技术上运用 self-attention ,仍然不可避免的会造成信息的丢失。我们主要是对在一系列连续的点中的时间上的变化进行建模感兴趣,也就是说,顺序本身起着最关键的作用。
transformer的过程
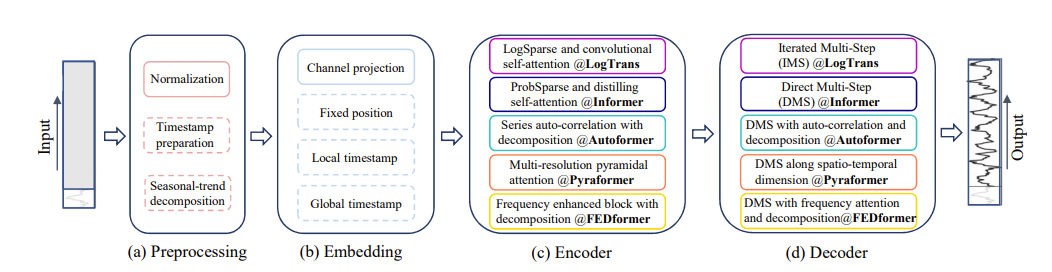
7问
Can existing LTSF-Transformers extract temporal relations well from longer input sequences?
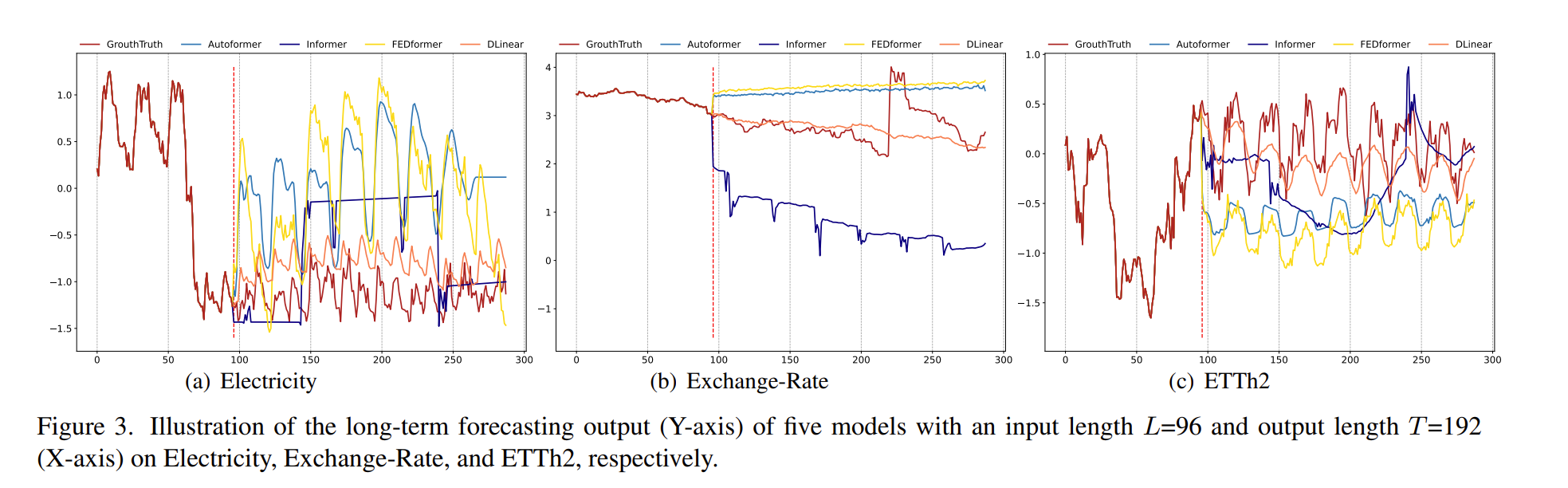
图肯定是最直观的。我来根据我的经验解释一下上面的图,就是你训练完模型后,扔进去几个步长的数据,预测接下来某些步长的数据。
红线前面是历史数据,后面则是预测的数据。
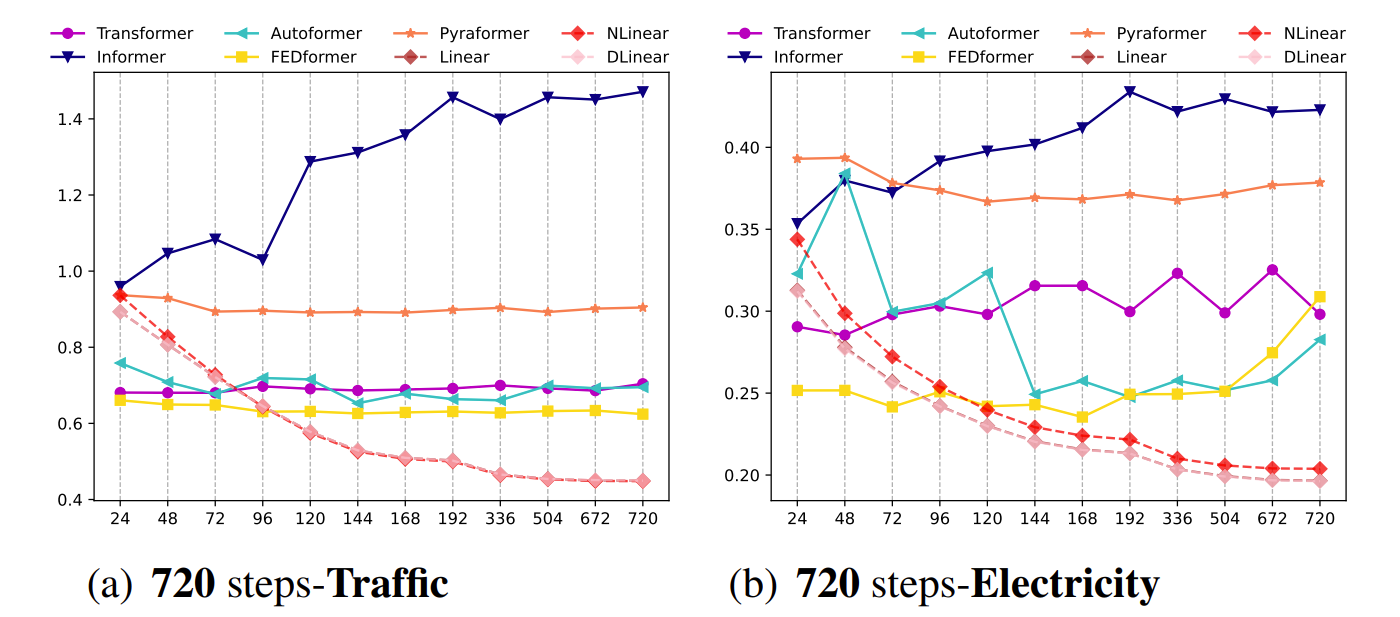
咱就是说,随着step的增加,和 transformer 相关的 mse 并没有下降,反而还有增加的
- What can be learned for long-term forecasting?
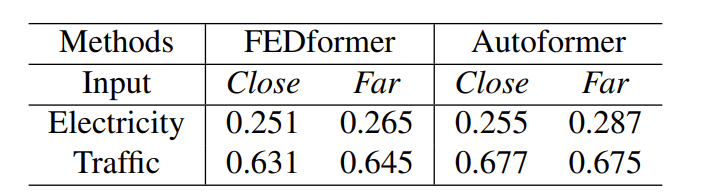
Table 3. Comparison of different input sequences under the MSE metric to explore what LTSF-Transformers depend on. If the input is Close, we use the 96th, …, 191th time steps as the input sequence. If the input is Far, we use the 0th, …, 95th time steps. Both of them forecast the 192th, …,(192 + 720)th time steps.
简单说就是对比,后96个步长和再后96个步长的MSE
历史窗口中的时间信息会显著影响短期时序预测的精度,而长期预测仅取决于模型是否能很好地捕捉趋势和周期性。也就是说,预测范围越远,历史窗口的影响就越小。从实验结果来看,Transformer模型的表现略有下降,这表明这些模型只能从相邻的时间序列中捕获相似的时间信息。
但这个我自己感觉的话说的比较牵强,下降是肯定会下降的,这么解释感觉有点不是很有道理。
- Are the self-attention scheme effective for LTSF?
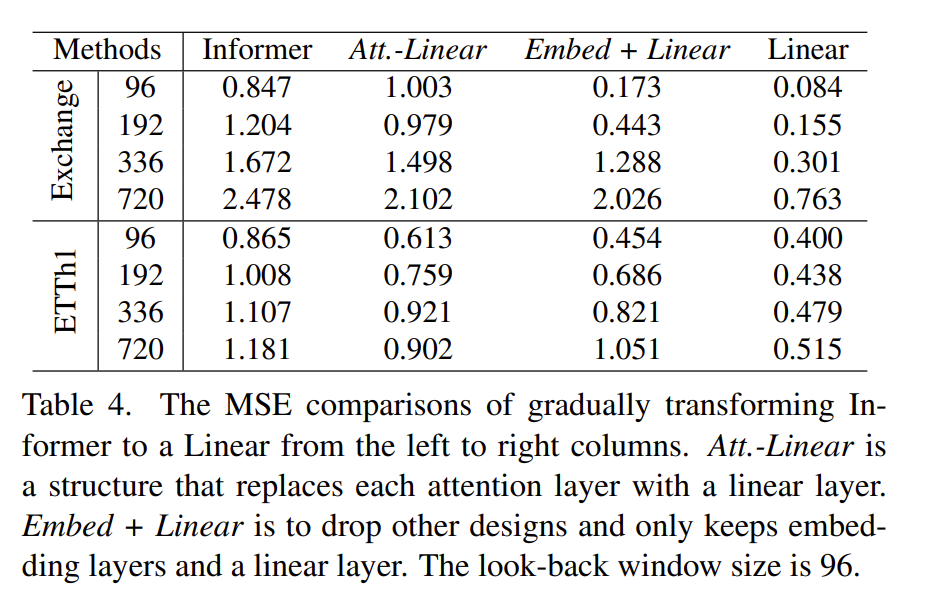
Att.-Linear – 用 linear 层换掉注意力机制
最后发现竟然是仅用线性的mse最小
- Can existing LTSF-Transformers preserve temporal order well?
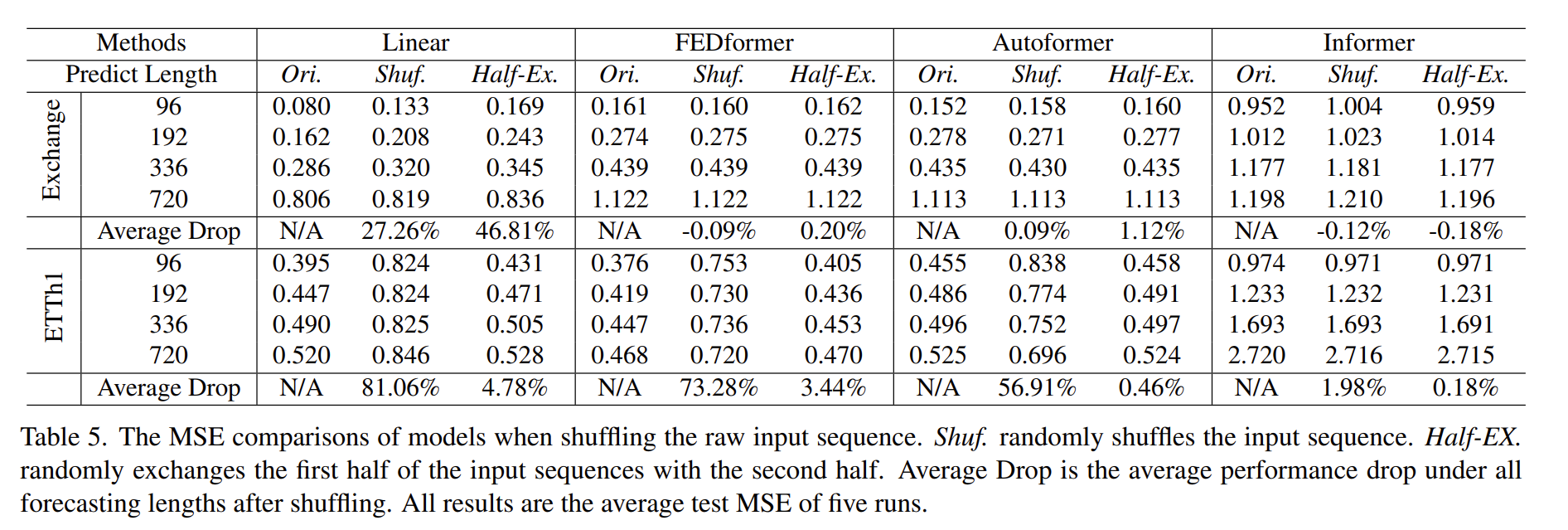
作者打乱了数据集,使其不具有时序性,可以看到transformer其实预测结果差别不大,用以证明其提取时序性的能力并不理想
- How effective are different embedding strategies?
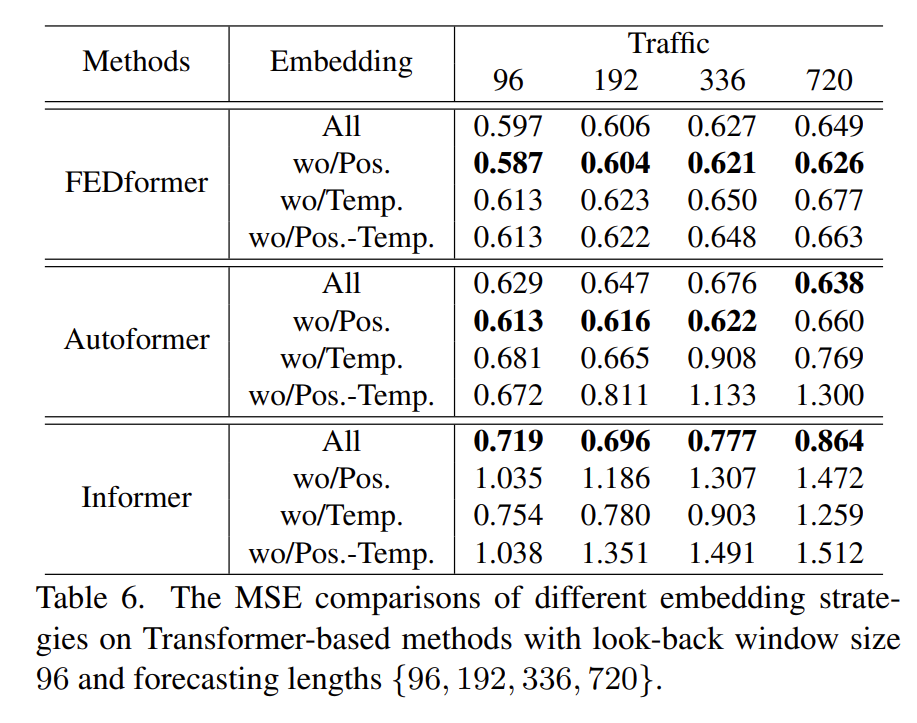
该问题也是问位置编码和时间戳嵌入技术对模型结果影响有多大?从图中的结果可知,如果没有位置嵌入(wo/Pos.),Informer 的预测误差将大幅增加。随着预测长度的增加,无时间戳嵌入(wo/Temp.)将逐渐损害Informer的性能。那是因为Informer对每个标记使用单个时间步长。FEDformer 和 Autoformer 不是在每个元素中使用单个时间步长,而是输入一系列时间戳来嵌入时间信息。然而,在没有时间戳嵌入的情况下,由于全局时间信息的丢失,Autoformer 的性能急剧下降。相反,由于 FEDformer 中提出的频率增强模块引入了时间归纳偏差,它在删除任何位置/时间戳嵌入方面受到的影响较小。
Is training data size a limiting factor for existing LTSFTransformers?
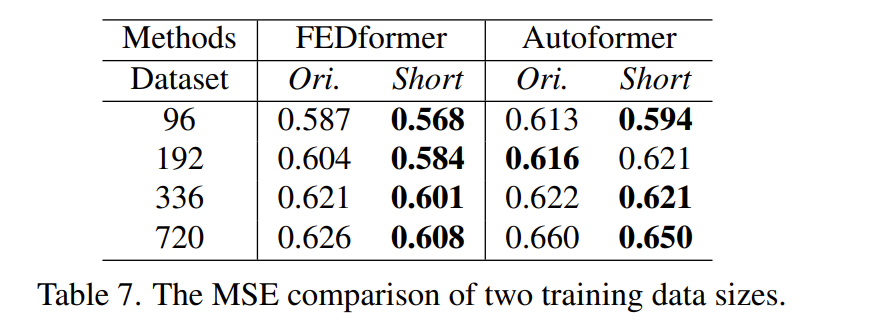
去不同规模的数据集来进行对比,发现相同步长下差别不大就是了
- Is efficiency really a top-level priority?
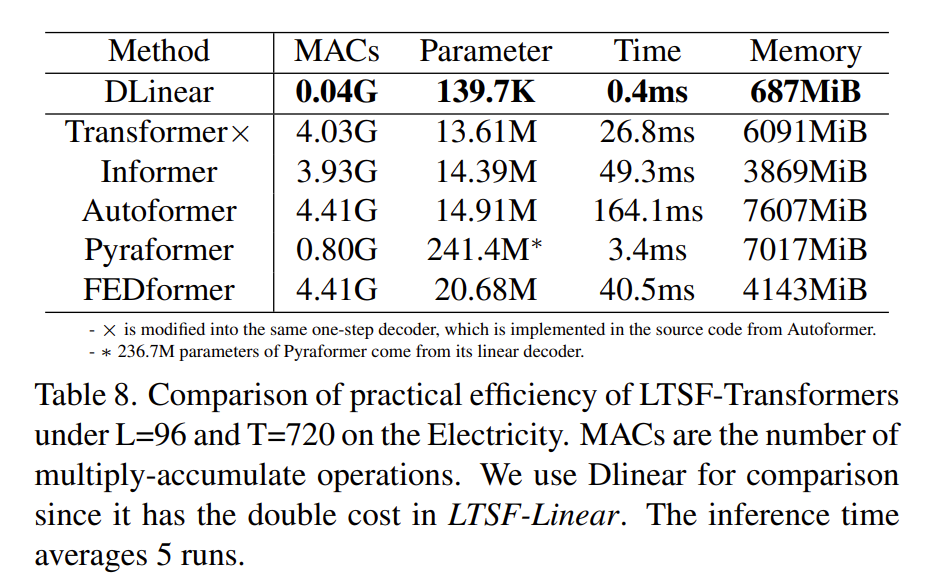
在实践中,大多数 Transformer 变体会造成更多的推理时间和更多的参数。这会引入了更多额外的设计元素,使得实际成本更高。此外,常规的 Transformer 的内存成本实际上是可以接受的,这削弱了设计内存高效的 Transformer 的重要性,至少对现有基准来说是这样。