bert论文阅读
之前听的李老师的课,现在来重新读一遍论文
论文阅读
https://arxiv.org/pdf/1810.04805.pdf
Abstract
首先解释一下bert是啥 Bidirectional Encoder Representations from Transformers
假如你已经了解了 transformers 模型, 那么仅凭这几个单词,你能想到什么?
首先肯定是这个 Encoder ,因为 transformers 中使用了 Encoder-Decoder 的架构,那么是不是可以推断,这里做了某些改进?Bidirectional –双向的。
我们先回顾一下 transformers 的架构 如下图:
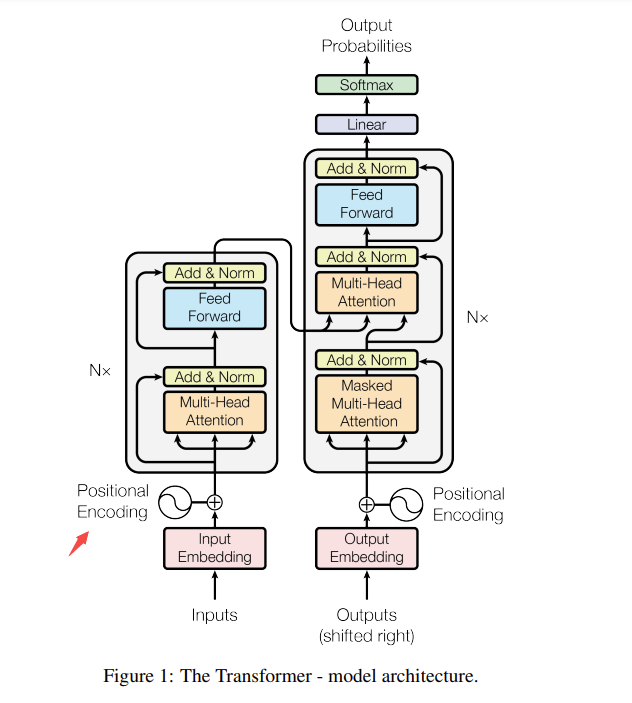
Encoder 是一个 Multi-Head Attention + MLP
双向?接着看论文。说是引用了 ELMo 这篇文章 。区别是 gpt 用了单向,但bert用了左侧和右侧的信息,所以说是双向。ELMo 用的是RNN的架构,而bert用的是transformers。
Intro
主要讲了bert如何在NLP上进行预训练。
两种预训练的方式
- ELMo 使用 RNN 提取特征 , 再把输入一起放进去。
- 基于gpt,在下游对训练好的参数进行微调
都使用单向语言模型(从左到右)来学习一般的语言表征(general language representations)
但是如果把两个方向都考虑进来,应该能考虑提升训练效果。
具体是如何做的呢?
- “masked language model” (MLM)
The masked language model randomly masks some of the tokens from the input, and the objective is to predict the original vocabulary id of the masked arXiv:1810.04805v2 [cs.CL] 24 May 2019 word based only on its context.
随意盖住一些词,预测哪些被盖住的词。这样,就允许你同时学到左右的信息。
- next sentence prediction
判断句子之间是不是相邻的,去学习句子层面的一些信息。
微调
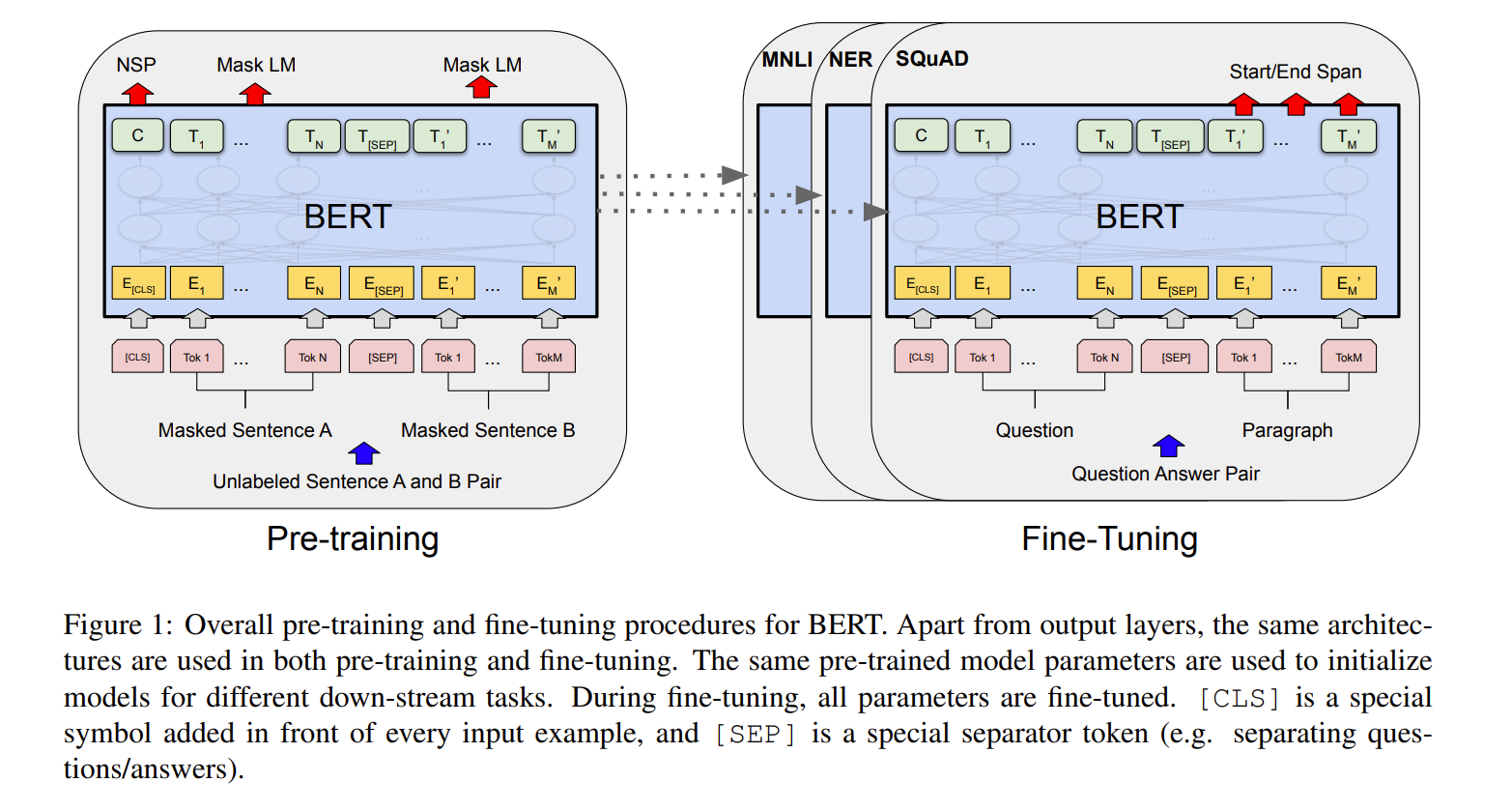
在预训练的时候,我们要做的是训练细一些没有标号的数据,训练一个bert模型。对每一个下游的任务,在前面的基础上进行微调。
架构
基于 transformer 调了几个参数。
| 参数 | meaning |
|---|---|
| L | number of layers (Transformer blocks) |
| H | hidden size |
| A | 多头注意力机制里头的个数 |
BERTBASE (L=12, H=768, A=12, Total Parameters=110M) and BERTLARGE (L=24, H=1024, A=16, Total Parameters=340M)
参考
【BERT 论文逐段精读【论文精读】】 https://www.bilibili.com/video/BV1PL411M7eQ/?share_source=copy_web&vd_source=280a52e4e83c4e8acf690970a8c45b25