VRT-- A Video Restoration Transformer 论文阅读
痛苦 没想到 最后还是要入坑CV QAQ~~
论文阅读
Abstract
现有的方法
- 滑动窗口策略(sliding window strategy)
- 递归结构(recurrent architecture)
这样的话就会被限制在逐帧恢复,或者缺乏大范围恢复的能力
于是提出了 Video Restoration Transformer (VRT)
为什么有效?
- 预测上采用了并行架构
- 拥有时间上长期建模能力
VRT由多个尺度(multiple scales,不知道这里这么翻合不合适)组成,每个尺度包含两个模型
- temporal mutual self attention (TMSA)
- parallel warping
然后讲了这两个模型的作用
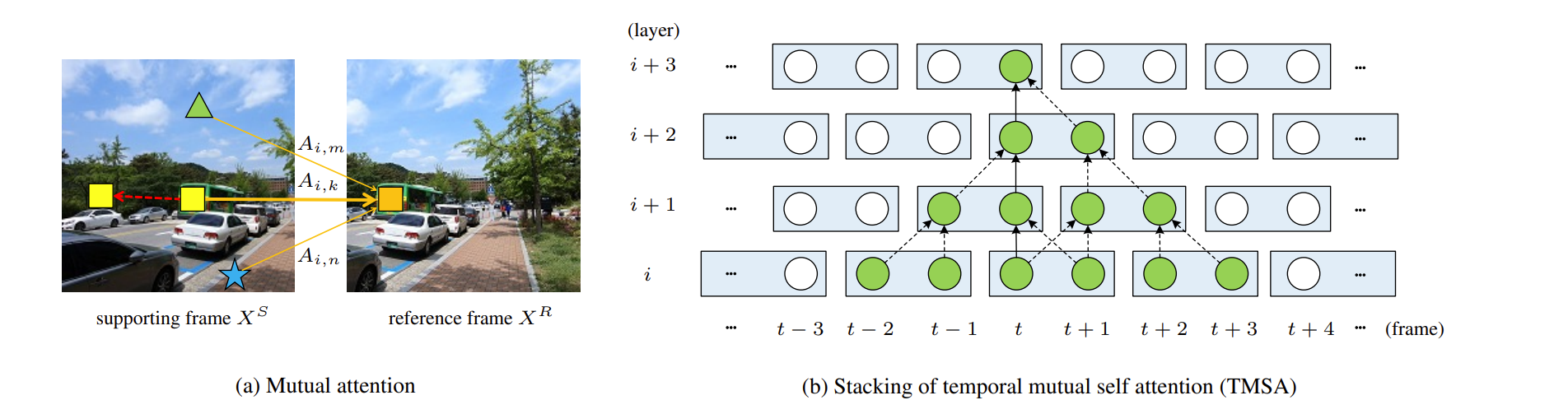
TMSA:将视频分成小的片段,然后采用 mutual-attenton 来进行联合运动估计、特征对齐和特征融合,自注意力用来做特征提取。为了实现夸片段的交互(信息提取、相互影响),对视频序列每隔一层进行一个 shift。
parallel warping:通过平行特征弯曲(parallel feature warping)进一步融合相邻帧的信息
Introduction
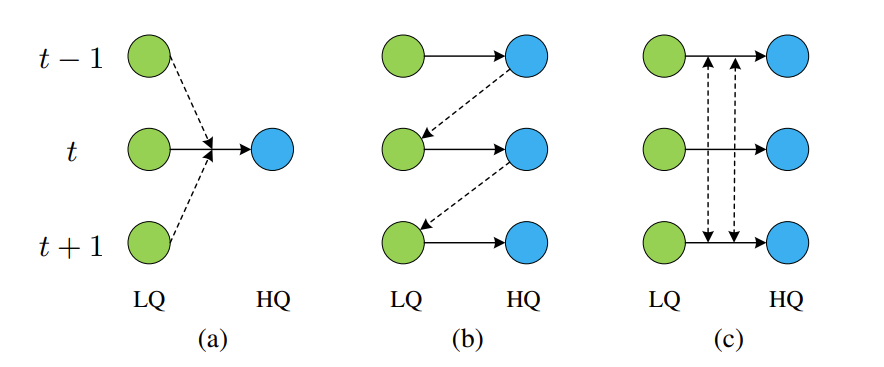
绿色圆圈:低质量(LQ)输入帧;蓝色圆圈:高质量(HQ)输出帧。t−1, t and t+1 are frame serial numbers。
a. 基于滑动窗口的方法。
基于滑动窗口的方法通常输入多帧来生成一个 HQ 帧,并以滑动窗口的方式处理长视频序列。
每个输入帧在推理过程中进行多次处理,导致特征利用效率低下和计算成本增加。
b. 递归方法
- 递归方法在并行上受到限制
- 递归模型不擅长长距离的时间依赖性建模,一个帧可能对下一帧有较明显的影响,但该影响在几个时间步长后会迅速消失,即帧间信息不能长距离传递
- 在帧数较少的视频上的表现明显下降
c.并行方法
基于多尺度框架,VRT将视频序列划分为不重叠的片段,并交替移动以实现片段间的互动,在每个尺度上都有几个TMSA模块,之后是平行的弯曲模块;
TMSA中,交互注意力的重点是相邻两帧片段之间的相互对齐,而自注意力则用于特征提取;
在每个尺度结束时,进一步采用平行翘曲操作将相邻帧的信息融合到当前帧。
与现有视频修复框架相比,VRT有以下优点:
- 如(C),VRT是在长视频序列上并行训练和测试的(基于滑动窗口的方法和递归的方法往往是逐帧测试的);
- VRT有能力对长距离时间依赖性进行建模,在每一帧的重建过程中利用多个相邻帧的信息(基于滑动窗口的方法不容易扩展到长序列建模,而递归方法在几个时间步长之后可能会忘记遥远的信息);
- VRT提出使用交互注意力来进行联合特征对齐和融合,它自适应地利用支持帧的特征并将其融合到参考帧中,可被视为隐式的运动估计和特征翘曲。
model
如下图,VRT由两个部分组成,特征提取模块(feature extraction)和重建模块(reconstruction)。
Feature Extraction:
在开始部分,采用一个2D卷积提取浅层特征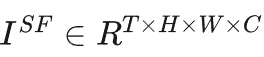 。然后,基于UNet架构设计了一种多尺度网络在不同分辨率进行特征对齐。
。然后,基于UNet架构设计了一种多尺度网络在不同分辨率进行特征对齐。
- 当总尺度数为 S 时,本文通过将每个 2×2 领域压缩到通道维度,并通过线性层叫通道数减少到原始数,对特征进行 S-1 次下采样;
- 然后,本文通过解压缩将特征逐渐上采样到原始尺寸。
在不同尺度,我们可以采用两个模块(Temporal Mutual Self-Attention与Parallel Warping)进行特征提取以及运动处理。最后,我们采用多个TMSA模块进一步进行特征提炼得到深层特征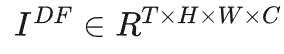 。
。
Reconstruction
在特征提取之后,本文同时从浅层特征和深层特征的相加中重建HQ帧(不同的帧是根据其相应的特征独立重建的)。为减轻特征学习的负担,本文采用全局残差学习(global residual learning),即只预测双线性上采样的LQ序列和真值HQ序列之间的残差。在具体实现中,不同的重建模块用于不同的修复任务:
- 对于视频超分,本文采用子像素层(sub-pixel convolution layer)对特征进行尺度因子为 S 的上采样;
- 对于视频去模糊、去噪,只需使用单个卷积层进行重建。
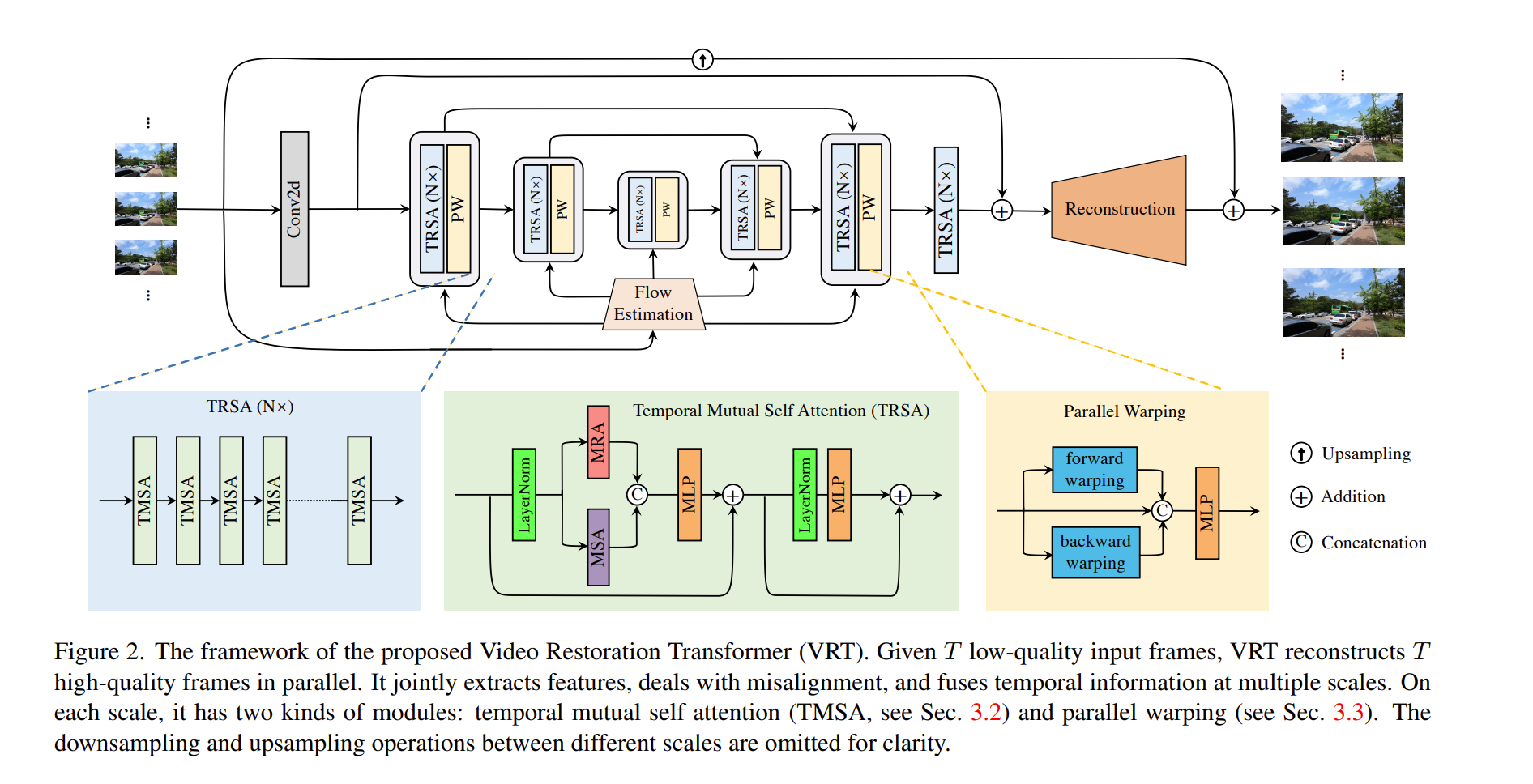
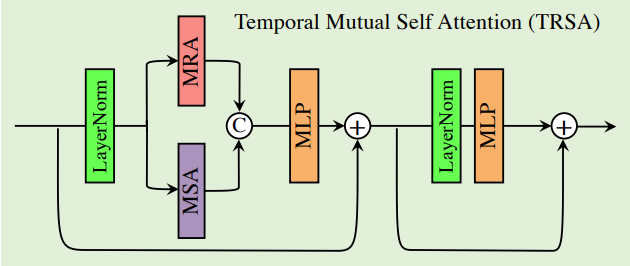
Temporal Mutual Self Attention
简单说一下,细节就看论文就好了
我们都知道,注意力机制就一个QKV。这里我们的Q用的是reference frame feature,KV用的是supporting frame feature

这样就可以得到reference frame feature 和 supporting frame feature的相关性
Temporal mutual self attention (TMSA)
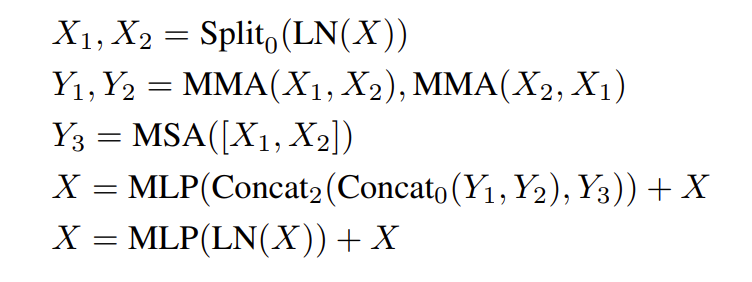
解释:将mutual attention与自注意力相结合
- 将两帧特征拆分为 X1,X2
- X1向X2 warping, X2向X1 warping –> 得到 Y1,Y2
- 同时MSA 计算得到 Y3
- Concat 以下然后扔到 MLP里降维
- 进一步 LayerNorm + MLP
tips: 如何解决计算效率问题?
每两帧都这么搞一下,计算复杂度是 T^2
解决方法: 采用类似于滑动窗口机制。并通过堆叠TMSA,一帧可以学到多帧的信息(2(i − 1) 帧)