New Directions in Automated Traffic Analysis 论文阅读
nPrint介绍
论文阅读
ABSTRACT
提出了nPrint这么一个东西,极大消除特征提取和模型调优。
INTRODUCTION
效果
看看效果
- 在 nPrint 上训练的模型可以执行细粒度的操作系统检测,在设备指纹识别方面比 Nmap 获得更高的精度,并且可以通过重传自动识别流量中的应用程序
- 在 netML(一个公开比赛) 上优于针对提取特征训练的性能最好的手工调优模型
数据如何表示?
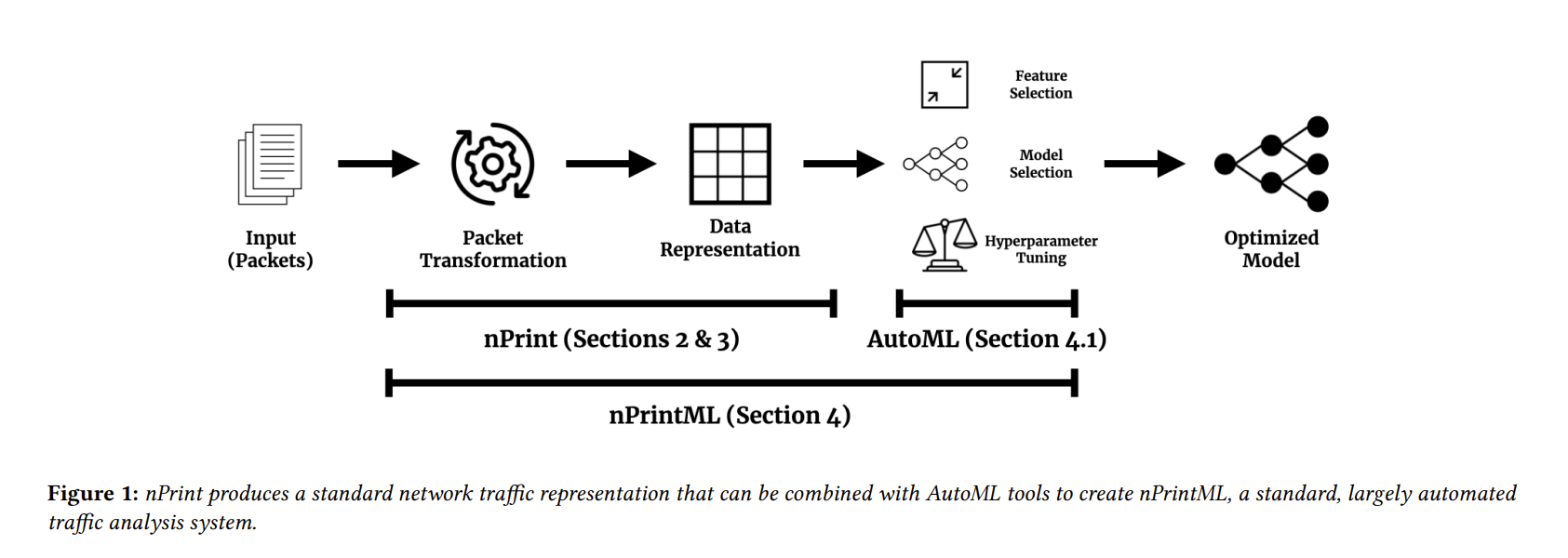
作者提出了三种表示方式
在应用机器学习方法时,对数据进行编码是非常重要的一环。为了实现上述提出的目标,数据编码需要满足以下要求:
- 完整性(Complete):我们的目的是找到一种统一的数据编码,而不依赖于专家知识,所以该编码方式需要包含数据包的所有信息。
- 不变性(Constant size per problem):机器学习模型要求输入的数据保持同样大小。因此,对于不同的数据包,也应该有相同的数据表征。
- 归一性(Inherently normalized):归一化可以减少模型的训练时间并提高模型的稳定性,因此数据表征应该是经过归一化的。
- 一致性(Aligned):不同数据包头的同一部分在编码后应该位于同样的位置。
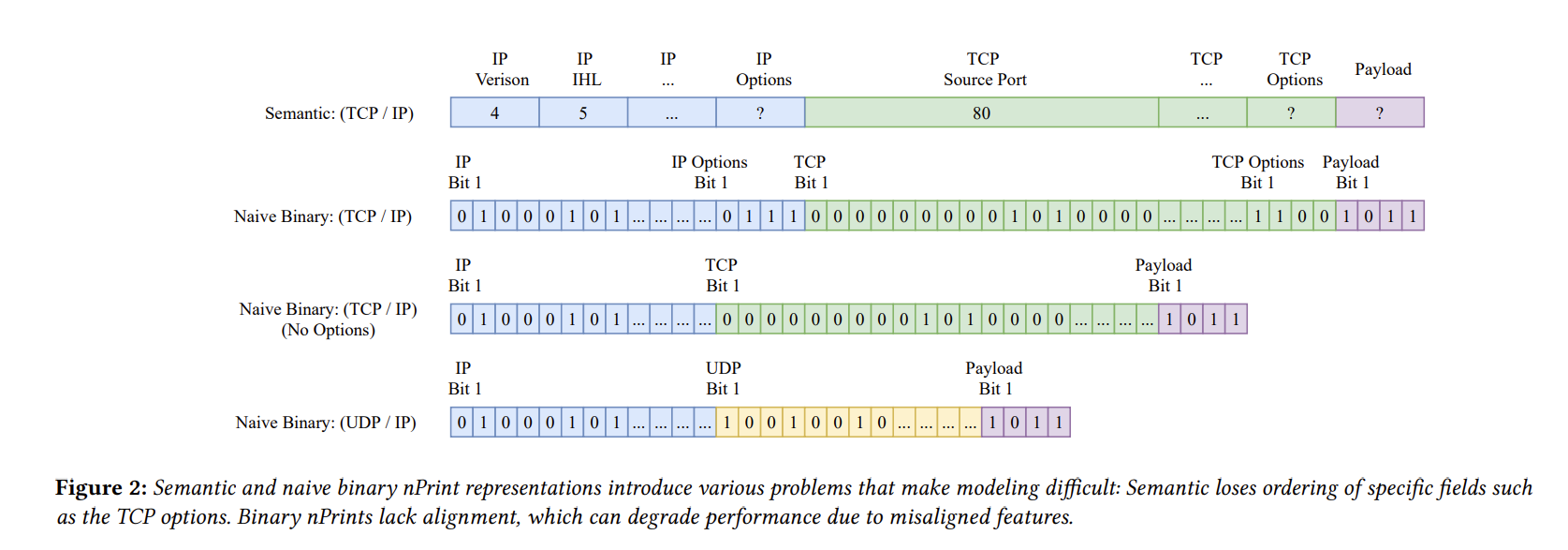
Semantic Representation
缺点:该表示不保留选项字段的顺序
Naive Binary Representation
可以通过 raw bitmap 的表示来保留顺序。但这样会忽略许多细节,如不同的size和协议。如下图,具有相同 IP 报头的 TCP 包和 UDP 包具有完全不同的信息,但却被表示为相同的特征。
而且会导致错位,会产生一下影响:
- 模型性能下降,因为在模型中可能存在重要特征的地方引入噪声
- 不可解释性,缺乏对应关系
Hybrid(作者提出的解决方案)
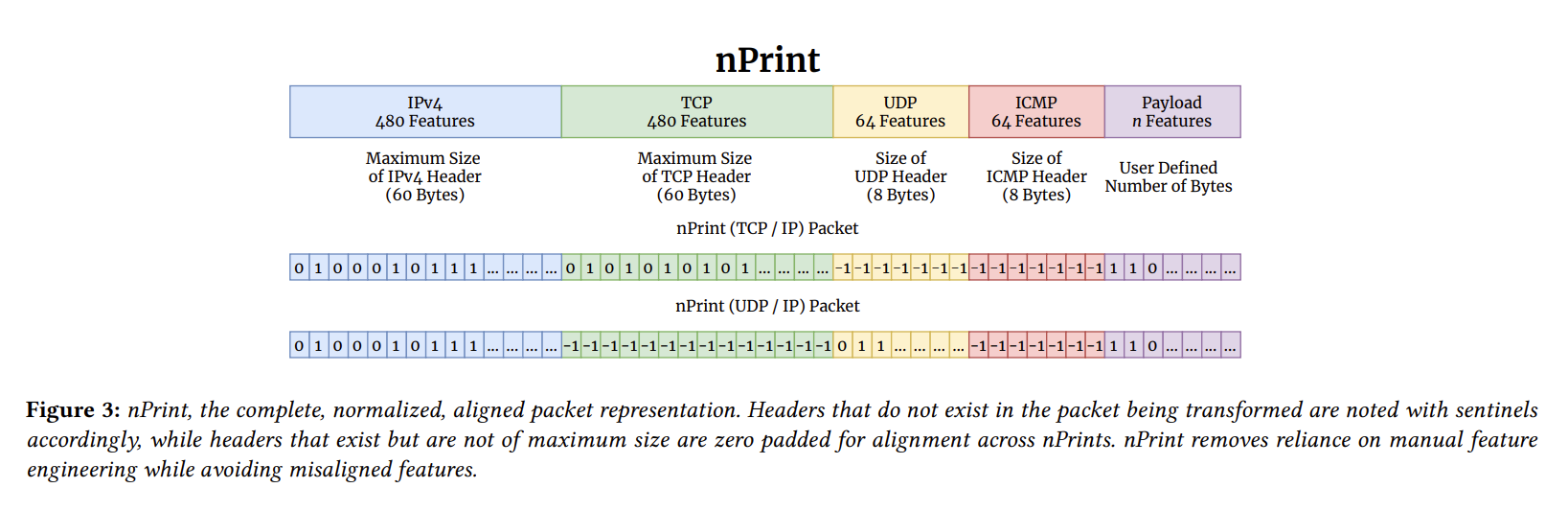
NPrint 是完整的、对齐的,每个问题的大小不变,并且本质上是规范化的。NPrint 完成了: 任何数据包都可以在不丢失信息的情况下表示。
- 对齐: 使用内部填充并为每个头类型包含空间,而不管这个头是否实际存在于给定的数据包中,都可以确保每个数据包以相同数量的特性表示,并且每个特性具有相同的含义。对齐使 nPrint 比许多网络表示具有明显的优势,因为它可以在位级进行解释。这允许研究人员和从业人员将 nPrint 映射回语义领域,以便更好地理解驱动给定模型性能的特性。并非所有的模型都是可解释的,但是通过具有可解释的表示形式,我们可以更好地理解可解释的模型。
- 规范化: 通过直接使用数据包的位并用 -1填充不存在的头,每个特性采用三个值中的一个: -1、0或1,消除了解析和表示每个数据包中每个字段的值的需要。此外,用 -1填充不存在的头值可以让我们区分设置为0的位和包中不存在的头。
- 大小不变: 每个数据包用相同数量的特性表示。对于给定的问题,我们将有效负载设置为可选的字节数: 随着越来越多的网络流量被加密,对于许多流量分类问题,有效负载将无法使用。
- NPrint 是模块化和可扩展的。首先,可以将其他协议(例如 ICMP)添加到表示中。其次,nPrint 是一种单包表示形式,可以用作需要数据包集的分类问题的构建块,正如我们在几个案例中所展示的那样。如果我们将每个 nPrint 指纹看作一个1xM 矩阵,其中 M 是指纹中的特征数,我们可以通过连接它们来构建多包 nPrint 指纹。
总结
该文章提出了一种很好的规范化数据包的手段,但是从作者的实验来看,也仅仅规范了数据包的头部,但是在一些识别中,对数据包的内容如何处理,仍然是个问题。