EfficientFormer -- Vision Transformers at MobileNet Speed 论文阅读
实训要中期检查了 嘟嘟嘟 Northeastern University 发的,看看
Abstract
由于众多的参数和模型(如注意力机制掺杂在里面),导致VIR(Vision Transformers)模型会慢于轻量级的卷积网络。因此,实时的部署是十分有挑战性的。
最近有些想要通过网络架构搜索(network architecture search)或用MobileNet block混合设计减少VIT的计算复杂度的尝试,但推理速度仍不能令人满意。
(ok 看到这里 肯定要去补一下 MobileNet 分开写就是了
大概意思就是一点点给模型”瘦身”, 重点是学习一下如何瘦身的。
然后大致介绍了一下自己提出的 fastest model, EfficientFormer-L1, 79.2% top-1 accuracy on ImageNet-1K with only 1.6 ms inference latency on iPhone 12 (compiled with CoreML), which runs as fast as MobileNetV2×1.4 (1.6 ms, 74.7% top-1), and our largest model, EfficientFormer-L7, obtains 83.3% accuracy with only 7.0 ms latency。
Introduction
为了减少 transformer 的延迟&计算时间,有一些方法已经被提出
- some efforts consider designing new architectures or operations by changing the linear layers with convolutional layers (CONV)
- combining self-attention with MobileNet blocks
- introducing sparse attention to reduce the computational cost
- efforts leverage network searching algorithm or pruning to improve efficiency
然后介绍论文中接下来了自己干了些什么事
- 重新审视了 VIT 和一些变体的设计原理通过延迟分析(latency analysis),使用 iPhone12作为测试平台,CoreML as the compiler
- 通过分析,证实了VIR中一些无效的设计和操作,并且提出了新的 dimension-consistent design paradigm for vision transformers
- 提出了一个简单仍有效的 latency-driven slimming method 来获得新的一类模型,EfficientFormers
Related Work
这里就不写了
On-Device Latency Analysis of Vision Transformers
然后介绍了四个发现
Patch embedding with large kernel and stride is a speed bottleneck on mobile devices
我们在下图中比较了具有large kernel and stride的Patch embedding模型(即 DeiT-S 和 PoolForm-S24)和没有它的模型(即 LeViT-256和 EfficientForm) ,表明Patch embedding反而是移动设备上的速度瓶颈。
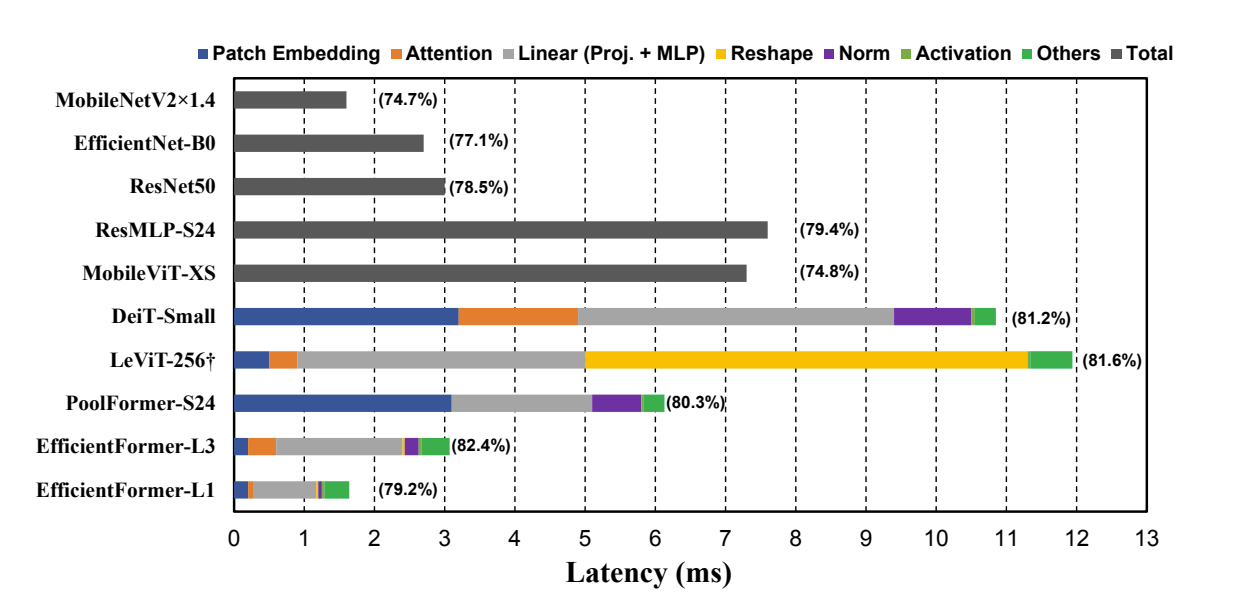
这图刚看上去可能有点不清晰,横向的长度代表耗费的 Latency , 主要是那两个长的蓝色条,代表了Patch embedding是有很大消耗的
- Consistent feature dimension is important for the choice of token mixer. MHSA is not necessarily a speed bottleneck.
比较了两种token mixers,pooling and MHSA
通过比较 PoolFormer-s24 和 LeViT-256 ,我们观察到重塑操作是 LeViT-256的瓶颈
发现如果维度一致且不需要reshape,MHSA 不会给手机带来显著的开销。虽然计算量大得多,但拥有一致的3D 特征的 DeiT-Small可以达到与新的 ViT 变体(即 LeViT-256)相当的速度。
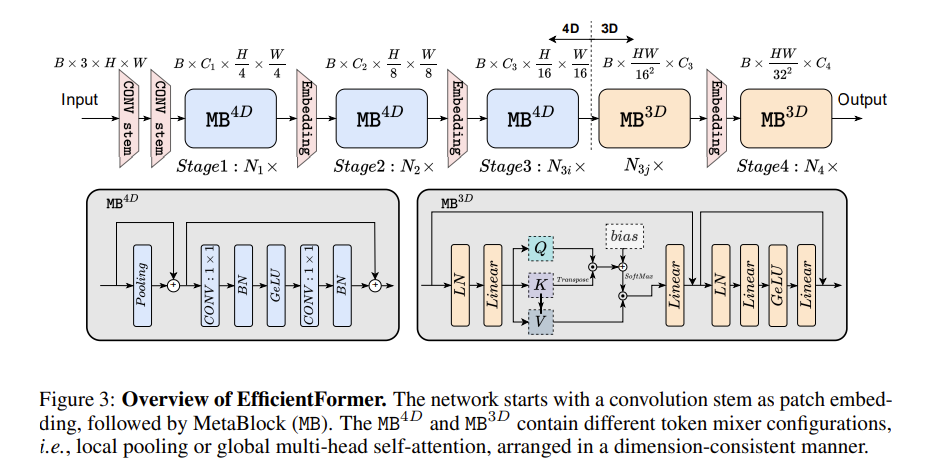
于是作者提出了一个 dimension-consistent network,同时具有4D 特征实现和3D MHSA,但效率低下的频繁reshape操作被消除。
- CONV-BN is more latency-favorable than LN (GN)-Linear and the accuracy drawback is generally acceptable
CONV-BN is more latency favorable because BN can be folded into the preceding convolution for inference speedup, while dynamic normalizations, such as LN and GN, still collects running statistics at the inference phase, thus contributing to latency
- The latency of nonlinearity is hardware and compiler dependent
We conclude that nonlinearity should be determined on a case-by-case basis given specific hardware and compiler at hand.
意思是不同的硬件可能用不同的线性层性能比较好,这要视硬件而定
Design of EfficientFormer
晚上回来看
知识补充
图像这块确实没了解过多少