恶意软件分析相关知识点
最近在读数据科学恶意软件分析(多久没读书啦),记录或复习一下学到的知识和一些方法
知识点记录
windows可移植可执行文件格式
综述
| 种类 | 主扩展名 |
|---|---|
| 可执行系列 | EXE, SCR |
| 库系列 | DLL, OCX, CPL, DRV |
| 驱动程序系列 | SYS, VXD |
| 对象文件系列 | OBJ |
PE格式设计目的:
告诉Windows如何将程序加载到内存中
描述文件的哪些块应该加载到内存中,以及在哪加载。windows应该在程序代码里的哪个位置开始执行程序,以及哪些动态链接代码库,应该加载到内存中。
为运行程序提供在执行过程中可能是用的媒体(或资源)
提供安全数据,例如数字代码签名
官方文档镇楼
https://learn.microsoft.com/zh-cn/windows/win32/debug/pe-format
简单来说,是由一系列头(header)、一系列节(section),接下来细说
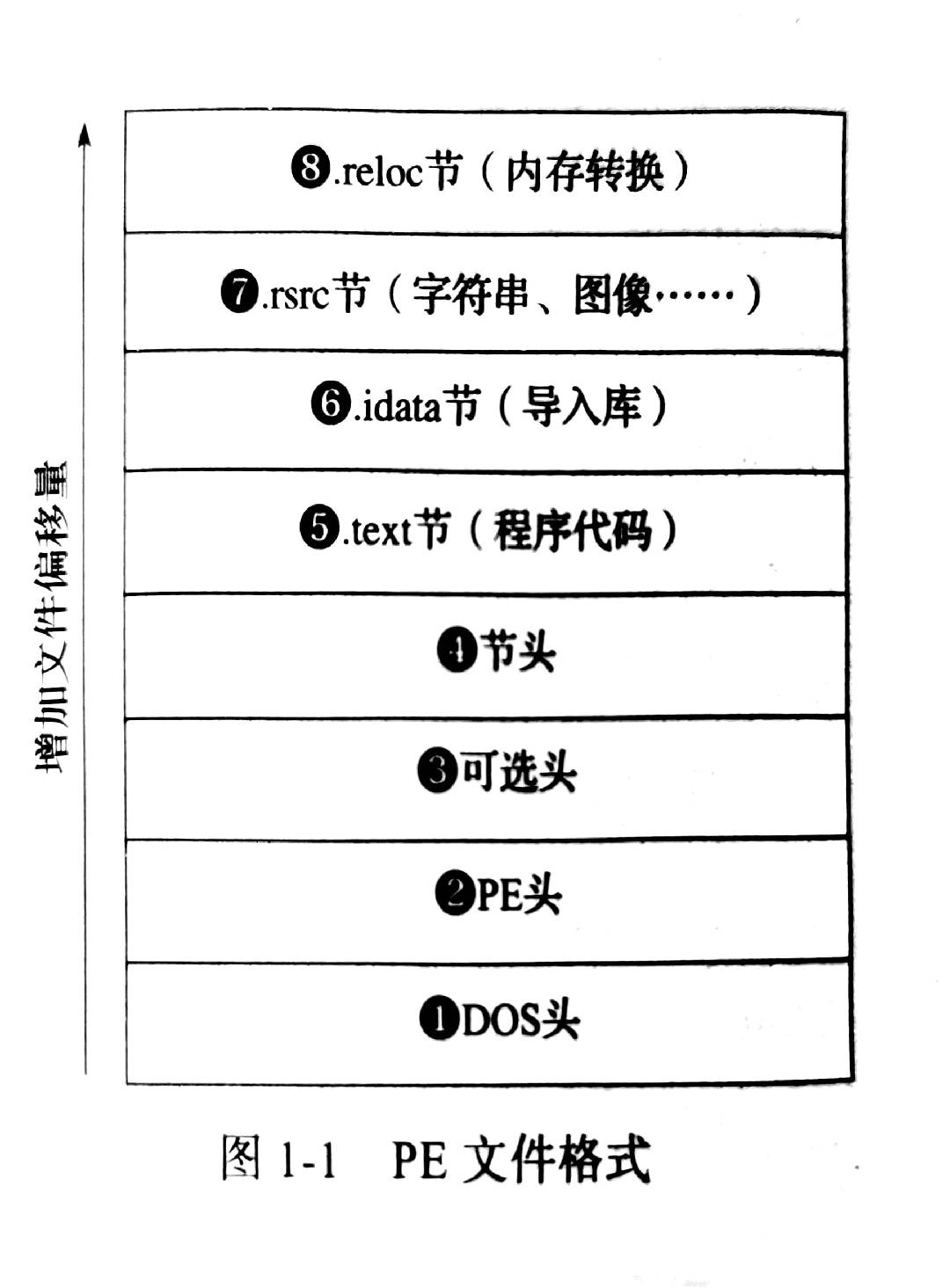
PE头
PE 文件头由 Microsoft MS-DOS 存根、PE 签名、COFF 文件头和可选标头组成。 COFF 对象文件头由 COFF 文件头和可选标头组成。 在这两种情况下,文件头后紧跟节标头。
MS-DOS Stub (Image Only)
Signature (Image Only)
COFF File Header
Machine Types
Characteristics
等等等等等等。。。。。。
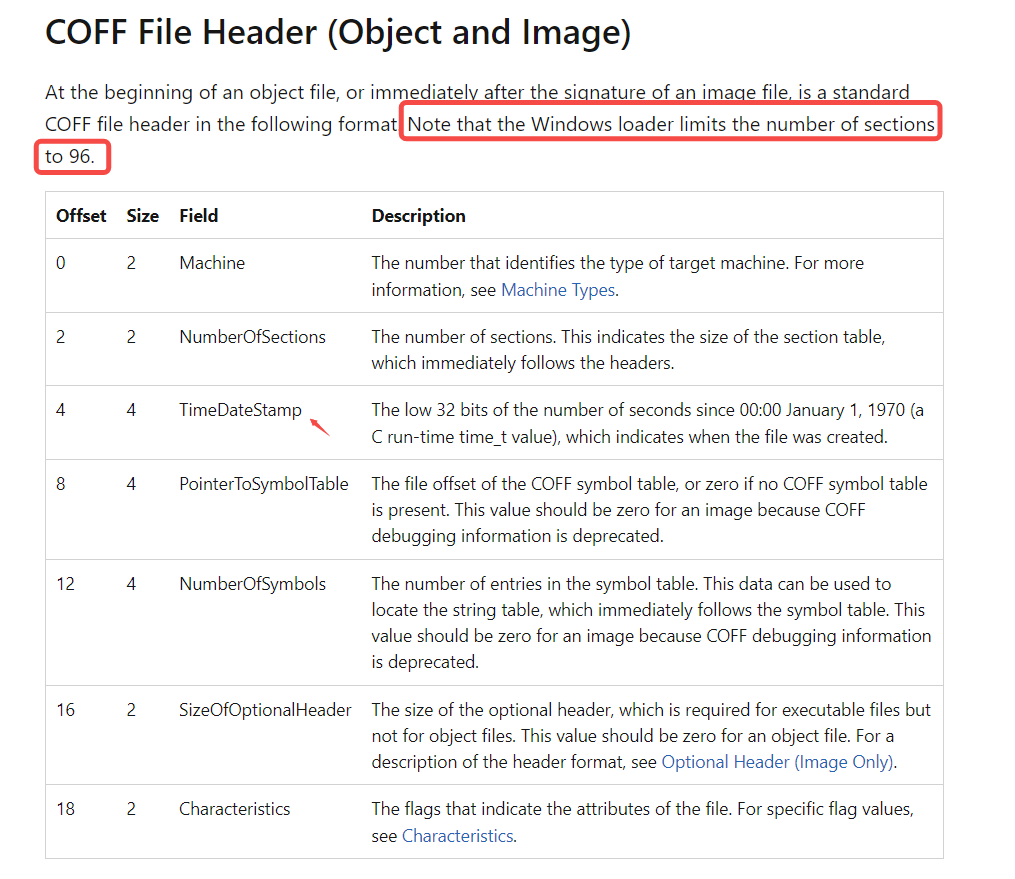
详细的去看官方文档,这里我们仅仅聊一下PE文件头在恶意文件分析中的作用。
- 时间戳字段 – 提供恶意软件作者编译文件的时间 ,but!!!作者可以伪造
- Machine Types – 指定 CPU 类型,判断针对32位还是64位还是别的等等
可选头
定义了PE文件中程序入口点的位置,该位置指的是程序加载后运行的第一个指令。它还定义了Windows在加载PE文件、Windows子系统
可选头,结构体为IMAGE_OPTIONAL_HEADER32,重要成员有9个:
- Magic:IMAGE_OPTIONAL_HEADER32为10B,IMAGE_OPTIONAL_HEADER64为20B
- AddressOfEntryPoint:持有EP的RVA值,指出程序最先执行的代码起始地址
- ImageBase:指出文件的优先装入地址(32位进程虚拟内存范围为:0~7FFFFFFF)
- SectionAlignment,FileAlignment:前者制定了节区在内存中的最小单位,后者制定了节区在磁盘文件中的最小单位
- SizeOfImage:指定了PE Image在虚拟内存中所占空间的大小
- SizeOfHeaders:指出整个PE头的大小
- Subsystem:区分系统驱动文件和普通可执行文件
- NumberOfRvaAndSize:指定DataDirectory数组的个数
- DataDirectory:由IMAGE_DATA_DIRECTORY结构体组成的数组
节头
.text: Contains the executable code of the program..data: Contains the initialized data..bss: Contains uninitialized data..rdata: Contains read-only initialized data..edata: Contains the export tables..idata: 导入地址表(IAT),列出了动态链接库和它们的函数。– IAT是做分析时最初需要查看的,因为它指出了程序所调用的库,这些调用反过来又可能会邪路恶意软件的高级功能。.reloc: Contains image relocation information. 和代码移动有关,逆向中可能十分有用。.rsrc: Contains resources used by the program, these include images, icons or even embedded binaries..tls: (Thread Local Storage), provides storage for every executing thread of the program.
在PE文件结构中的数据节包括 .rsrc, .data, .rdata , 他们存储程序使用的鼠标光标图像、按钮图标、音频和其它媒体等。
这里需要重点关注 .rsrc , 通过检查PE文件中的可打印字符串,图形图像和其他资产,可以获得关于文件功能的重要线索。
这里提一嘴:icoutils 工具包。
n-gram
N-Gram是一种基于统计语言模型的算法。它的基本思想是将文本里面的内容按照字节进行大小为N的滑动窗口操作,形成了长度是N的字节片段序列。
该模型基于这样一种假设,第N个词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。
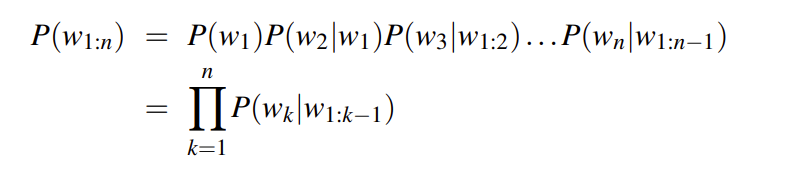
马尔可夫猜想
The assumption that the probability of a word depends only on the previous word is Markov called a Markov assumption
只依赖前一个词
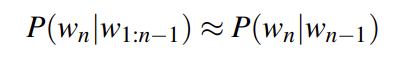
于是 用N的代表 n-gram 得到
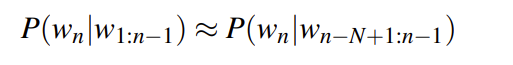
n-gram的n大小对性能的影响
n更大的时候
对下一个词出现的约束性信息更多,更大的辨别力,但是更稀疏,并且n-gram的总数也更多,为 V^n个(V为词汇表的大小)n更小的时候
在训练语料库中出现的次数更多,更可靠的统计结果,更高的可靠性 ,但是约束信息更少
杰卡德(Jaccard)相似度
判断相似度的方法有很多 如:余弦定理,Jaccard系数,曼哈顿距离
但在处理恶意文件的时候我们常用的方法还是Jaccard系数
Jaccard相似系数是衡量两个集合的相似度一种指标。
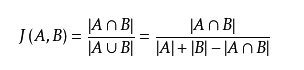
Jaccard主要应用场景:
- 推荐系统
- 过滤相似度很高的新闻,或者网页去重
- 考试防作弊系统
- 论文查重系统
力导向算法
用处:尽可能最小化局部失真。
是对弹簧力和磁力的物理模拟。将网络中的边模拟为物理弹簧,往往可以得到较好的节点定位。
二分网络
二分网络是一个所有节点可以划分为两个分区(组)的网络,其中任何一个部分都不包含内部连接。这种类型的网络可以用来展示恶意软件样本之间的共享属性。
共享代码分析 – 包含了自己的一些想法
特征袋 (bag of features)
我们不是把样本看作一个由函数、导入的动态库等等组成的互相连接的系统,而是把恶意软件看作是一系列便于计算的独立特征袋。
在恶意软件分析中,用N-gram提取一个恶意软件样本进行API调用的N-gram序列。然后将恶意软件表示为一个特征袋,并使用N-gram特征将恶意软件样本与其他的一些恶意软件样本的 N-gram 进行比较,从而将序列信息整合进特征袋模型中。
这里我来结合自己的理解谈一谈 N-gram 的优缺点:
首先 N-gram 是序列提取特征的 , 这点和 RNN 是类似的。
如果说,API调用是按顺序的,那么,这种预测方式可以很好的践行。但如果,顺序之间可以是任意的,也许就会学到一些不好的东西。那么就会导致我们判断共享代码的时候,预测效果的下降。
这里好比 RNN 和 transformer, 为什么说 transformer 在很多场景更好?因为transformer 基于注意力机制,有更好的并行性,不一定是像RNN一样, 用 t1,t2,… , tn-1 去 预测 tn。
书中用的是 N-gram , 但是用 transformer 可能会有更好的结果 ,这块论文没有去阅读过,但是在这个transformer火爆的年代可能是一种很好的实践。
说到这里我还想到了上星期刷到的一篇文章,transformer 对时序预测真的有效吗? 发表于 AAAI 2023
但我认为,至少在 恶意代码的检测上是有效的。具体可以看我之前总结的(写的不是很好
https://b1ue0ceanrun.github.io/2022/05/23/attention-learn
https://b1ue0ceanrun.github.io/2022/03/09/attention
相似性
可以从哪些方面来计算哪些相似性
- 基于指令序列的相似性
- 基于字符串的相似性
- 基于导入地址表的相似性
- 基于动态API调用的相似性
机器学习方法检测恶意文件
特征提取
我感觉,包括之前和带我的师傅聊过。特征提取是非非非非非非常重要的一部分。
那我们要从哪些角度来进行特征提取呢?
- 是否有数字签名
- 存在格式错误的头部文件
- 包含加密数据
- 是否在超过100多个网络工作站出现过
评价指标 – ROC曲线
这个当时机器学习课上就有讲过,哈哈,还做了一次课程作业。
简单来说,就是鱼和熊掌不可兼得,检出率和误报率不可兼得。
检出率(True Positive Rate, TPR): 系统正确检测出的恶意软件样本的百分比。
误报率(False Positive Rate, FPR):系统错误报警的正常样本的百分比。
基准率(Base Rate, BR):检测系统检测的二进制文件集中恶意软件的百分比。
AUC(Area Under Curve)被定义为ROC曲线下与坐标轴围成的面积,显然这个面积的数值不会大于1。又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间。AUC越接近1.0,检测方法真实性越高;等于0.5时,则真实性最低,无应用价值。
source
https://web.stanford.edu/~jurafsky/slp3/3.pdf